Tpsit
I sistemi distribuiti
Le architetture dei sistemi informativi si sono sviluppate ed evolute nel corso degli anni passando da schemi centralizzati a modelli distribuiti.
Un sistema informatico si dice distribuito se almeno una delle seguenti due condizioni è verificata:
- elaborazione distribuita: le applicazioni risiedono su più host che collaborano tra loro;
- base di dati distribuita: il patrimonio informativo è ospitato su più host.
Alle applicazioni vengono dati nomi diversi in funzione dei diversi ruoli:
- Cliente (client)
- Servente (server)
- Attore (actor): quando assume sia il ruolo di cliente che quello di servente.
Classificazione dei sistemi distribuiti
- Sistemi di calcolo distribuiti che generalmente sono configurati per il calcolo ad alte prestazioni:
- cluster computing: connessione di computer omogenei allo scopo di parallelizzare l’elaborazione.
- grid computing: la cooperazione di calcolo può essere effettuata anche utilizzando macchine eterogenee.
- Sistemi informativi distribuiti: tra questi sistemi troviamo il Web, che risulta essere il più grande sistema distribuito.
- Sistemi distribuiti pervasivi che sono una nuova generazione di sistemi che hanno tipicamente connessioni di rete wireless che generalmente sono sottoparti di sistemi più grandi.
Vantaggi dei sistemi distribuiti 👍🏼
Affidabilità
Grazie alla sua ridondanza è in grado di “sopravvivere” ad un guasto di un suo componente.
Integrazione
Capacità di un sistema distribuito di integrare componenti spesso eterogenei tra loro, sia per tipologia hardware, sia per sistema operativo.
Sono stati definiti appositi linguaggi come XML e notazioni JSON per favorire lo scambio di informazioni nel web e permettere un’agevole ed efficiente pubblicazione di dati complessi.
Trasparenza
Come trasparenza si intende il concetto di vedere il sistema distribuito non come un insieme di componenti ma come un unico sistema di elaborazione.
Esistono otto forme di trasparenza:
- di accesso: accedere a risorse locali e remote con le stesse operazioni, in modo unico e uniforme.
- di locazione: nascondere dove è localizzata una risorsa e permettere di accedere a essa senza conoscerne la locazione.
- di concorrenza: si permette ai processi di operare in maniera concorrente.
- di replicazione: le operazioni di duplicazione vengono effettuate all’insaputa degli utenti.
- ai guasti: viene mascherato il guasto e il recovery di una risorsa.
- alla migrazione: si nasconde l’eventuale spostamento di una risorsa senza interferire sulla sua modalità di accesso.
- alle prestazioni: vengono nascoste le operazioni necessarie per riconfigurare il sistema al variare del carico.
- di scalabilità: il sistema viene espanso senza interrompere o modificare il funzionamento.
Economicità
Generalmente i sistemi distribuiti offrono spesso un miglior rapporto prezzo/qualità dei sistemi centralizzati basati su mainframe.
Apertura
Con la definizione di protocolli standard si favorisce l’apertura all’hardware e software di fornitori diversi in modo da avere:
- interoperabilità: implementazioni diverse su elaboratori di diverso tipo possono coesistere per comporre un unico sistema.
- portabilità: un’applicazione sviluppata su un sistema operativo può funzionare su di un altro presentando la medesima interfaccia all’utente in modo da non modificare l’operatività.
- ampliabilità: è relativamente semplice far crescere il sistema aggiungendo sia componenti hardware che software.
Connettività e Collaborazione
Nei sistemi distribuiti la possibilità di condividere risorse hardware e software comporta vantaggi economici. Per esempio è possibile condividere apparecchiature speciali di costo elevato, quali stampanti particolari, plotter, ecc..
Prestazioni e scalabilità
La crescita di un sistema distribuito con l’aggiunta di nuove risorse e, quindi, di nuovi servizi, fornisce a tutti i suoi componenti un miglioramento delle prestazioni e permette di sostenere l’aumento del carico di richieste: questa possibilità prende il nome di scalabilità orizzontale.
Tolleranza ai guasti
La possibilità di replicare risorse offre una certa garanzia di tolleranza ai guasti; la presenza di un componente guasto non deve pregiudicare il funzionamento del sistema ma, al limite, introdurre solo inefficienze in termini di tempo di risposta.
Svantaggi legati alla distribuzione 👎🏼
Complessità
Proprio per la struttura hardware i sistemi distribuiti sono più complessi di quelli centralizzati: richiedono strumenti per la l’interconnessione degli host e tecniche per l’instradamento corretto dei messaggi.
Sicurezza
Con la connessione di più host tra loro si crea la possibilità di accedere a dati e risorse anche a chi non ne ha il diritto: nascono nuove problematiche connesse alla sicurezza che nel caso di sistemi centralizzati erano inesistenti.
Comunicazione
Il trasferimento a distanza delle informazioni richiede nuove tipologie di sistemi di telecomunicazione, sia cablati sia wireless, e l’aumento esponenziale degli utenti fa sì che giornalmente aumenti la richiesta di bande trasmissive, anche per migliorare la qualità del servizio offerto.
Evoluzione dei sistemi distribuiti
Architetture distribuite hardware: dalle SISD al cluster di PC
Esistono diverse possibilità per classificare le architetture hardware. Noi ricordiamo quella di Flynn che si basa sui due flussi di informazioni normalmente presenti nei calcolatori:
- Flusso delle istruzioni
- Flusso dei dati
| Dati singoli | Dati multipli | |
|---|---|---|
| Istruzioni singole | SISD | SIMD |
| Istruzioni multiple | MISD | MIMD |
SISD
Un elaboratore come la macchine di Von Neumann che ha un solo flusso dati e un solo flusso istruzioni è una macchina Single Instruction stream - Single Data stream (SISD): tutte le macchine che hanno una singola CPU come i personal computer, le workstation e i mainframe appartengono a questa categoria.
SIMD
Nelle macchine SIMD l’elaborazione avviene su più flussi dati in contemporanea ma con un singolo flusso di istruzioni.
MISD
A questa categoria appartengono gli elaboratori che eseguono più istruzioni sullo stesso flusso dati: nel modello di calcolo MISD esistono quindi più processori, ognuno con un proprio flusso di istruzioni che verranno eseguite sullo stesso flusso di dati.
Con questa tipologia di architettura a oggi non sono ancora state costruite macchine da commercializzare.
MIMD
L’architettura Multiple Instruction stream - Multiple Data stream comprende tutte le tipologie di elaboratori composti da più unità centrali di elaborazione indipendenti che possono lavorare su stream di dati anch’essi indipendenti.
Viene effettuata un ulteriore classificazione delle macchine MIMD in riferimento a come è suddivisa la memoria fisica, e cioè possiamo avere:
- Macchine MIMD a memoria fisica condivisa → multiprocessor
- Macchine MIMD a memoria privata→ multicomputer
Cluster computing
Con cluster computing si intende un sistema distribuito costituito da un insieme di nodi ad alte prestazioni interconnessi tramite una rete locale ad alta velocità: devono essere omogenei, cioè i singoli nodi hanno lo stesso sistema operativo, hardware molto simile e sono connessi attraverso la stessa rete.
Differisce da una rete di PC principalmente per:
- la potenza di elaborazione ad alte prestazioni
- la velocità del trasferimento dati
- la centralizzazione fisica delle macchine, tutti i PC sono montati sullo stesso rack
- la presenza di una applicazione di management che permette di lanciare processi su altri PC, monitorare il loro comportamento ecc.
Abbiamo due possibili architetture:
- Organizzazione gerarchica con singolo nodo principale
- organizzazione Single System Image: per esempio MOSIX, che effettua un bilanciamento automatico del carico effettuando una eventuale migrazione di processi.
Grid computing
Con grid computing si intende un sistema distribuito di calcolo altamente decentralizzato, composto da un grand numero di nodi disposti a griglia (grid) e caratterizzati da un grado elevato di eterogeneità sia per hardware, per il software, la tecnologia di rete, le politiche di sicurezza e molto altro.
Sistemi distribuiti pervasivi
Questa è una nuova generazione di SD i cui nodi sono piccoli, mobili, con connessioni di rete wireless e spesso facenti parte di un sistema più grande.
Reti domestiche e domotica
Le reti domestiche sono caratterizzate dall’assenza di un amministratore di sistema e generalmente sono sistemi completamente auto-configuranti e autogestiti in quanto generalmente gli utenti non hanno conoscenze specifiche di connettività
Wearable computing
Oggi i sistemi wearable computing sono essenzialmente utilizzati per l’assistenza sanitaria ed effettuano il monitoraggio di parametri biologici o memorizzando i dati in un computer palmare oppure trasmettendo i dati a un sistema di archiviazione remoto.
Architettura a terminali remoti
Tutte le operazioni vengono effettuate da un’unica entità centrale alla quale sono collegati terminali privi di capacità di elaborazione che si limitano a visualizzare e inviare e ricevere le informazioni alla entità centrale.
Architettura client-server
I client richiedono un servizio a un server di competenza, che è in grado di esaudirne la richiesta, la elabora e invia la risposta.
Possono essere presenti più server che offrono più servizi contemporaneamente così come più client possono richiedere lo stesso servizio o servizi differenti sia a server diverso che allo stesso server.
Inoltre un server può essere contemporaneamente anche client: quindi può essere server per uno, o più, servizi e client per altri richiedendo i servizi che necessita ad altri server.
Architettura WEB-centric
L’evoluzione che negli ultimi anni ha caratterizzato i sistemi distribuiti riguarda il Web: la diffusione capillare delle piattaforme mobili ha provocato uno spostamento delle applicazioni sul server facendo regredire gli host quasi a host utilizzati solo per l’interfaccia grafica verso l’utente.
Il Web server è il centro del sistema distribuito al quale i client vi accedono per ottenere dei servizi: tutta la computazione avviene sui server che restituisce ai client il risultato.
Architettura cooperativa
L’evoluzione dell’architettura client-server è l’architettura cooperativa che si basa su entità autonome che esportano e richiedono servizi secondo il modello di sviluppo a componenti per la programmazione lato server proprio della programmazione a oggetti.
Architettura completamente distribuita
In opposizione alla architettura Web-centric troviamo l’architettura completamente distribuita, tipica di sistemi dove è necessaria la cooperazione di gruppi di entità paritetiche, come nei sistemi groupware, che dialogano tra loro offrendo ciascuno i propri servizi e richiedendo servizi che spesso risultano essere duplicati per garantire l’immunità ai guasti.
Architettura a livelli
Per alleggerire il carico elaborativo dei serventi sono state introdotte le applicazioni multilivello, nelle quali avviene la separazione delle funzionalità logiche del software in più livelli.
Si introducono gli strumenti di middleware, cioè uno strato software in mezzo che si colloca sopra al sistema operativo ma sotto i programmi applicativi, e sono l’evoluzione dei sistemi operativi distribuiti.
Tra le funzionalità del middleware troviamo:
- I servizi di astrazione e cooperazione
- I servizi per le applicazioni
- Il servizio di comunicazione
La comunicazione nel Web con protocollo HTTP
HTTP e il modello client - server
Il Web è basato sul modello client - server.
I client sono elementi attivi che richiedono pagine Web ai server e ne visualizzano il contenuto.
I server sono elementi passivi che rimangono in ascolto di eventuali connessioni di nuovi client su una determinata porta TCP, secondo un modello a server passivo e forniscono ai client le pagine Web o le risorse richieste.
HTTP è un protocollo usato per trasmettere risorse, non solo file. Una risorsa è identificata da un URI o URL.
- URI (Uniform Resource Identifier): set generico di nomi o indirizzi che rappresentano stringhe assegnate alle risorse
- URL (Uniform Resource Locator): termine informale, utilizzato solo nelle specifiche tecniche, associato a popolari protocolli quali HTTP, FTP, ecc..
Il protocollo HTTP
Http, acronimo di Hyper Text Transfer Protocol, è un protocollo che consente di inviare e ricevere le risorse Web da un host chiamato server a un altro chiamato client.
Per comunicare utilizza le sessione, dove ciascuna inizia stabilendo per prima cosa una connessione TCP al server, utilizzando di default la porta TCP 80, effettuando poi una request contenente un URL. In risposta il server produce e restituisce il file richiesto e, nella situazione più semplice, chiude la connessione TCP immediatamente dopo.
Conversazione Client - Server
Ogni conversazione tra client e server sul Web inizia con una richiesta rappresentata da un messaggio di testo creato dal client in formato HTTP. Il client invia la richiesta al server, quindi attende la risposta.
Tipi di connessioni
Il protocollo HTTP utilizza TCP come protocollo di trasporto per effettuare le connessioni tra client e server.
Nella connessione di HTTP 1.1 di tipo permanente il server lascia aperta la connessione TCP dopo aver spedito la risposta. Le successive richieste e risposte fra client e server utilizzano sempre la stessa connessione.
Esistono due tipi di connessioni permanenti:
- connessione permanente incanalata → le richieste vengono via via aggiunte a una coda chiamata pipeline, mentre le risposte vengono processate e inviate nello stesso ordine delle richieste.
- connessione permanente non incanalata → il client passa una nuova richiesta solo quanto la risposta alla precedente è stata ricevuta.
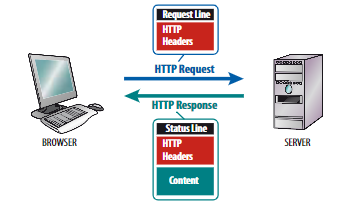
HTTP Request
La prima riga della request contiene la versione del protocollo HTTP utilizzato, mentre nelle righe successive vengono indicate gli header, rappresentate da diversi elementi, ciascuno dei quali composto da un nome, seguito dai due punti e da un valore.
Gli header più comuni sono:
- la versione del browser che prende il nome di User-Agent
- l’host presente nell’URL
Una http request è un messaggio testuale inviato dal client al server HTTP ed è formato da tre elementi:
- riga di richiesta,
- intestazione HTTP (header)
- corpo del messaggio (message body)

Riga di richiesta
La riga di richiesta contiene:
- Il metodo:
GET
HEAD
POST
PUT
DELETE
OPTIONS
- l’URI (o URL) è l’identificativo di risorsa richiesta
- la versione
Intestazione HTTP
L’intestazione HTTP contiene tutte le informazioni necessarie per l’identificazione del messaggio ovvero i vari header (esempio: content-type: text/html).
Corpo del messaggio
Il corpo del messaggio di richiesta contiene i dati trasportati.
Messaggio di risposta: HTTP Response
- Una riga iniziale con versione protocollo e stato
- un’intestazione facoltativa
- un corpo facoltativo.
Metodi HTTP
Le applicazioni RESTful consentono di effettuare operazioni da remoto sui dati presenti nei server, che lo permettono, sfruttando i metodi del protocollo HTTP. Le operazioni di tipo CRUD (Create, Retrieve, Update, Delete) possono essere così descritte:
- chiedere dati al server (
GET)
- creare dati sul server (
POST)
- modificare o sostituire i dati sul server (
PUT)
- cancellare dati sul server (
DELETE)
I codici di stato
I codici di stato, o status code, sono dei codici restituiti dai server HTTP per indicare al client l’esito di una richiesta.
100-199(Information): questi codici di risposta forniscono informazioni temporanee alla richiesta, durante il suo svolgimento e a partire dalla versione 1.0 viene sconsigliato il loro utilizzo.
200-299(Successful): questo intervallo di codici di stato indica il completamento di una richiesta con successo.
300-399(Redirection): questi codici vengono utilizzati per comunicare una varietà di stati che non indicano un errore, ma che richiedono un trattamento particolare da parte del browser.
400-499(Client error): questo intervallo di valori viene utilizzato per indiCare le condizioni di errore provocate dal comportamento del client.
500-599(Server error): è una classe di messaggi di errore, prodotti come risposta a problemi verificatisi sul server.
Le applicazioni Web e il modello client - server
Due concetti fondamentali stanno alla base delle applicazioni Web:
- Tecnologie client - side e server - side
- linguaggi di mark-up e linguaggi di programmazione
Tecnologie del Web
Possiamo distinguere le tecnologie del Web in due gruppi:
- Tecnologie client - side: sono le strutture tecnologiche in cui l’elaborazione avviene sul client, tipicamente nel browser:
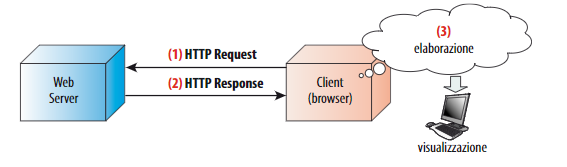
- Tecnologie server - side: sono le strutture tecnologiche in cui l’elaborazione avviene sul server, tipicamente nel Web server:
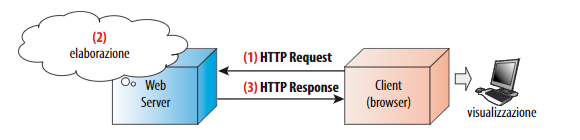
Linguaggio del Web
Nel web vengono utilizzate due tipologie di linguaggi: i linguaggi di mark-up e i linguaggi d programmazione.
- I linguaggi di mark-up servono a scrivere documenti strutturati, come
HTML,XML,JSON
- I linguaggi di programmazione servono a scrivere programmi, come
JavaePHP.
Il modello client - server
Il modello client-server è costituito da un insieme di host che gestiscono una (o più) risorse, i server, e da un insieme di client che richiedono l’accesso ad alcune risorse distribuite.
Non sono gli host ad essere server o client ma i processi che sono in esecuzione su di essi, dove come processo si intende un programma in esecuzione.
Lo schema di funzionamento di un modello client - server:
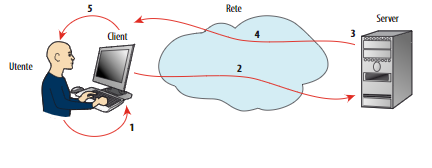
- Il client manda una richiesta al server
- il server riceve la richiesta
- il server esegue il servizio richiesto
- il server manda una risposta ed eventualmente dei dati
- il client riceve la risposta
Alcuni servizi tipici delle architetture Client - Server sono:
- Telnet
- HTTP
- FTP
- SMTP, IMAP4, e così via.
Comunicazione unicast e multicast
- Unicast: il server comunica con un solo client alla volta accettando una richiesta di connessione solo se nessun altro client è già connesso.
- Multicast: al server possono essere connessi più client contemporaneamente.
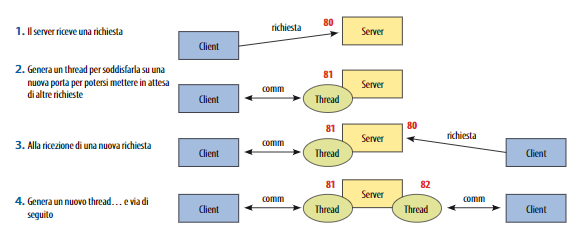
Livelli e strati
Le architetture client - server sono normalmente organizzate a “livelli” (tier) dove ogni livello corrisponde a un nodo o gruppo di nodi di calcolo su cui è distribuito il sistema.
In genere nelle applicazioni possiamo individuare tre tipi principali di funzionalità che corrispondono a una struttura in tre strati:
- front-end o presentation tier: interfaccia verso l’utente
- logica applicativa o middle tier (business logic)
- back-end con accesso alle risorse e ai dati, anche detto data tier.
Solitamente viene utilizzata questa nomenclatura:
- Presentation Layer (PL): composta dall’insieme delle procedure o moduli dedicate all’acquisizione e alla presentazione dei dati all’utente
- Resource Management Layer: è composto dall’insieme delle procedure che gestiscono i dati
- Business Logic Layer: è il corpo centrale dell’applicazione che comprende la logica della elaborazione.
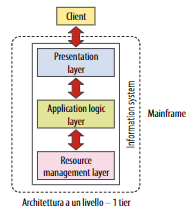
Architettura a un livello - 1 tier
Questa architettura non rientra nella tipologia client -server e può essere classificata come architettura a un solo livello.
Tutta l’elaborazione è effettuata dall’elaboratore centrale e i terminali servono solo per I/O.
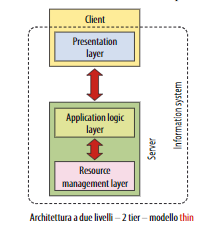
Architettura a due livelli - 2 tier
- un livello server
- un livello client
Possiamo individuare due sottocategorie:
- il modello Thin-client, dove il server è responsabile della logica applicativa e gestione dei dati e il client è responsabile della visualizzazione:
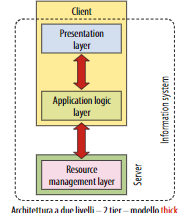
- Il modello Thick-client dove il server è responsabile della gestione dei dati mentre il client è responsabile della logica applicativa e della presentazione:
 💡Il limite delle architetture client - server a due livelli è che sono poco scalabili dato che il server deve gestire la connessione e lo stato della sessione di ciascun client.
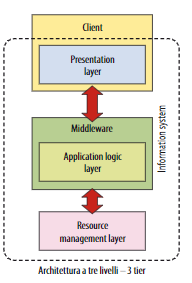
💡Il limite delle architetture client - server a due livelli è che sono poco scalabili dato che il server deve gestire la connessione e lo stato della sessione di ciascun client.Architettura a tre livelli - 3 tier
- front-end o presentation tier
- logica applicativa o middle tier
- back-end con accesso alle risorse e ai dati, detto data tier.
I vantaggi dell’introduzione del middleware sono notevoli, soprattutto in termini di prestazioni, in quanto in questo modo si favorisce la distribuzione della quantità di elaborazione.
Nei sistemi 3-tier è però più difficile la progettazione, lo sviluppo e l’amministrazione.
Architetture multi-tier
Le architetture client - server a N livelli sono una generalizzazione del modello client - server a tre livelli dove vengono scomposti e introdotti un numero qualunque di livelli e server intermedi.
💡Questa scomposizione viene effettuata per suddividere ulteriormente i compiti dei vari strati: prende il nome di multi-tier
Le applicazioni di rete
Il livello applicazione implementa i vari protocolli, tra cui:
- SMTP
- FTP
- HTTP
- DNS
Non va quindi confusa l’applicazione con il livello di applicazione: il livello di applicazione è lo strato protocollare che mette a disposizione i protocolli mediante i quali le applicazioni possono comunicare tra host remoti.
Applicazioni di rete
In generale un’applicazione di rete è costituita da un insieme di programmi che vengono eseguiti su due o più computer contemporaneamente.
Identificazione di un servizio mediante socket
Per individuare il processo viene utilizzato un identificatore unico per l’host, chiamato numero di porta.
Il client contatta il server usando l’identificatore dell’host (indirizzo IP) + l’identificatore del servizio (numero di porta)
Un numero di porta non può essere associato a più processi ma un server può offrire più servizi, ciascuno su un’apposita porta.
Questo meccanismo prende il nome di socket (I socket e la comunicazione con i protocolli TCP/UDP).
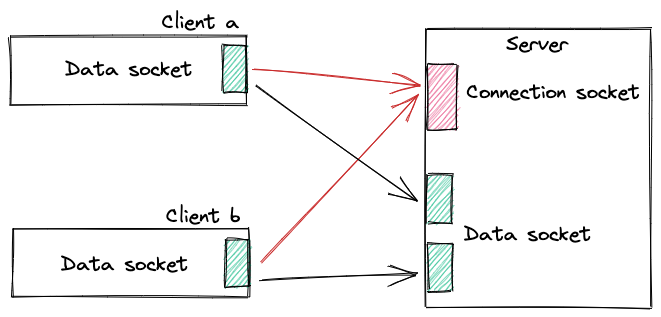
Il server offre il servizio a più client e deve gestire la concorrenza: il socket di connessione è anche chiamato socket di benvenuto e alla richiesta accettata di un client il server crea dinamicamente un nuovo thread e gli assegna un socket di connessione.
Architettura per l’applicazione di rete
- Client server
- Peer to peer
- Architetture ibride
Architettura client server
La caratteristica principale è che deve sempre esserci un server attivo che offre un servizio restando in attesa che uno o più client si connettano a esso per poter rispondere alle richieste che gli vengono effettuate.
Un client non è in grado di comunicare con gli altri client ma solo con il server: più client invece possono comunicare contemporaneamente con lo stesso server.
Architettura Peer to Peer
In questo tipo di architettura abbiamo coppie di host chiamati peer che dialogano direttamente tra loro
- P2P decentralizzato
Un peer ha sia funzionalità di client che di server ed è impossibile localizzare una risorsa mediante un indirizzo IP statico.
Le risorse che i peer condividono sono dati, la memoria, la banda ecc..
- P2P centralizzato
è un compromesso tra il determinismo del modello client - server e la scalabilità del sistema puro: ha un server centrale che conserva informazioni sui peer e risponde alle richieste su quelle informazioni effettuando quindi la ricerca in modalità centralizzata.
I peer sono responsabili di conservare i dati e le informazioni.
- P2P ibrido
è un P2P parzialmente centralizzato dove sono presenti alcuni peer determinati dinamicamente che hanno anche la funzione di indicizzazione: gli altri nodi sono anche chiamati leaf peer.
Servizi offerti dallo strato di trasporto
Ogni applicazione deve scegliere tra i protocolli di trasporto quale deve adottare per realizzare un protocollo applicativo in base ai servizi che sono necessari alle specifiche esigenze della applicazione, che possono essere:
- Trasferimento dati affidabile,
- ampiezza di banda
- temporizzazione
- sicurezza
Trasferimento dati affidabile
Intendiamo un servizio che garantisce la consegna completa e corretta dei dati.
Ci sono due protocolli:
- UDP: protocollo senza connessione da utilizzarsi quando la perdita di dati è un fatto accettabile in quanto non è affidabile.
- TCP: orientato alla connessione da utilizzarsi quando la perdita di dati è un evento inaccettabile.
Ampiezza di banda
Alcune applicazioni necessitano di una garanzia sulla larghezza di banda minima disponibile, come la trasmissione di un evento in diretta in una web - TV.
Temporizzazione
Alcune applicazioni per essere “realistiche” ammettono solo piccoli ritardi per essere efficaci: lo strato di trasporto non è in grado di garantire i tempi di risposta perchè le temporizzazioni presenti assicurano un certo ritardo end-to-end tra le applicazioni.
Il protocollo TCP garantisce la consegna del pacchetto ma non il tempo che ci impiega e neppure il protocollo UDP, nonostante sia più veloce del TCP, è temporalmente affidabile.
Sicurezza
Un’applicazione può richiedere allo strato di trasporto la cifratura di tutti i dati trasmessi in modo tale che anche se questi venissero intercettati da malintenzionati non si perda la riservatezza.
È quindi possibile che vengano richiesti dei servizi di sicurezza da applicare per garantire l’integrità e la riservatezza dei dati.
Applicazione di rete
I processi hanno la necessità di scambiare messaggi con gli altri processi della medesima applicazione, per comunicare tra loro questi processi devono mettersi in contatto tramite i loro indirizzi e utilizzare i servizi offerti dal livello di applicazione.
La pila protocollare di Internet (TCP/IP) è costituita da cinque livelli:
- Applicazione (Messaggio)
- Trasporto (Segmento)
- Rete (Datagram)
- Collegamento (Frame)
- Fisico (Segnale fisico)
TCP e UDP svolgono funzioni diverse, cioè offrono servizi diversi allo strato applicativo:
- il protocollo TCP è orientato alla connessione (connection - oriented) ed è affidabile
- il protocollo UDP è senza connessione (connectionless) e quindi non affidabile.
Le porte di comunicazione e i socket
Ogni PC ha una sola porta fisica di connessione al network, perciò sono state introdotte le porte logiche che identificano il processo corretto.
Questo numero di porta viene definito port address oppure sinteticamente port, in questo modo è possibile instaurare simultaneamente più comunicazioni cosicchè due applicazioni possono comunicare l’una con l’altra indipendentemente dal fatto che sulla rete stiano avvenendo altre comunicazioni.
Il numero di port è specificato su 2 Byte, da 0 a 65535.
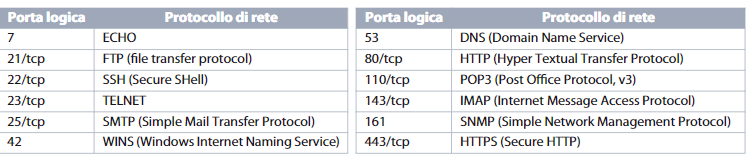
- I port da 0 a 1023 sono riservati ad applicazioni particolari, costituiscono i cosiddetti well-know port numbers.
- I port da 1024 a 49151 sono riservati a porte registrate e sono usasti da alcuni servizi ma possono anche essere utilizzati dai client.
- I numeri di porta da 49152 a 65535 sono liberi per essere assegnati dinamicamente dai processi applicativi.
Alcuni esempi
L’identificazione di un servizio avviene quindi combinando l’indirizzo IP dell’host e della porta logica, metodo che prende il nome di socket.
Esiste una struttura chiamata association che consente d’identificare ogni singola connessione in modo univoco e che contiene le seguenti informazioni:

Socket e i processi client - server
Quando un client apre un socket non dovrebbe utilizzare una porta nota, in quanto riservata per l’offerta di servizi.
La connessione tramite socket
Il concetto di socket è stato sviluppato come estensione diretta del paradigma UNIXX di I/O su file, si basa sulla sequenza:
- Open: permette di accedere al file
- Read/Write: accedono ai contenuti del file
- Close: terminazione dell’utilizzo del file.
Le funzioni utili per l’utilizzo dei socket in Java sono:
ServerSocket(): crea un nuovo socket
close(): termina l’utilizzo di un socket
bind(): collega un indirizzo di rete a un socket
listen(): aspetta messaggi in ingresso
accept(): comincia a utilizzare una connessione in ingresso
connect(): crea una connessione con un host remoto
write()trasmette dati su una connessione attiva
read(): riceve dati da una connessione attiva
Famiglie e tipi di socket
Esistono varie famiglie di socket, dove ogni famiglia riunisce i socket che utilizzano gli stessi protocolli, in particolare ricordiamo:
- Internet socket (AF_INET): è quella che permette il trasferimento di dati tra processi posti su macchine remote connesse tramite LAN
- Unix Domain Socket (AF_UNIX): permette il trasferimento di dati tra processi sulla stessa macchina Unix
La principale differenza tra queste due famiglie è l’indirizzo:AF_UNIX è praticamente il pathname valido nel file system della macchina.
AF_INET è specificato in due valori:
- Indirizzo IP che individua un unico host internet
- Numero di porta che specifica una particolare porta dell’host
Tipi di socket
I socket sono di tre tipi:
- Stream socket
- Datagram socket
- Raw socket
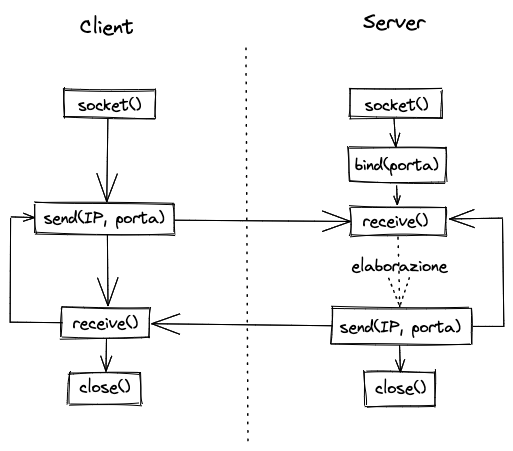
Stream socket
Con gli stream socket si realizza una connessione sequenziale tipicamente asimmetrica, affidabile e full-duplex basata su stream di byte di lunghezza variabile.
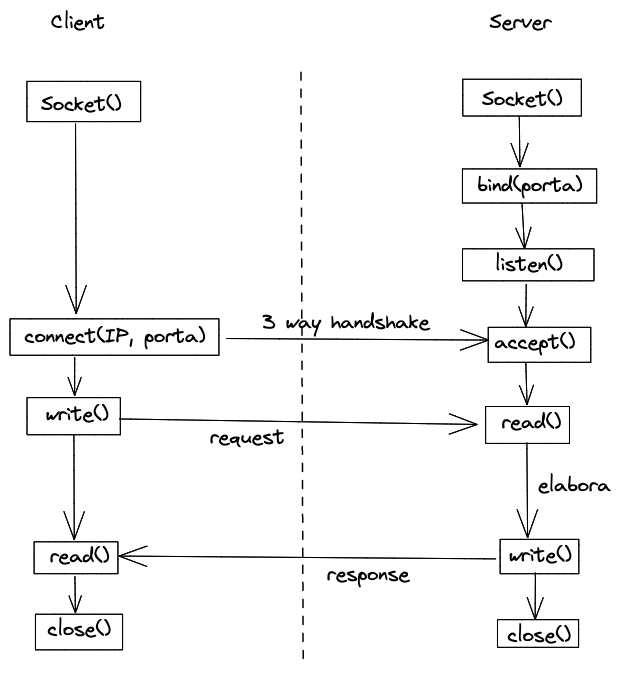
Ogni processo crea il proprio endpoint richiamando la primitiva socket() e successivamente:
- Il server si mette in ascolto e quando gli arriva una richiesta la esaudisce mediante la primitiva
accept()che crea un nuovo socket dedicato alla connessione
- il client si pone in coda sul socket del server e quando viene accettato dal server crea implicitamente il binding con la porta locale.
Datagram socket
Con i datagram socket viene realizzata la comunicazione che permette di scambiare dati senza connessione mediante il trasferimento di datagrammi che inoltrano messaggi di dimensione variabile, senza garantire ordine o arrivo dei pacchetti.
Ogni processo crea il proprio endpoint richiamando la primitiva che crea il socket e successivamente:
- Il server si mette in attesa di ricevere i dati e alla loro ricezione può inviare una risposta
- Il client invia il pacchetto di dati al server e può mettersi in attesa di una risposta con le stesse primitive che ha utilizzato il server.
Al termine della comunicazione il socket viene chiuso.
Trasmissione unicast e multicast
L’unicast è la normale situazione in cui un mittente invia e un destinatario riceve con eventualmente l’inversione dei ruoli, mentre il multicast è utilizzato per trasmettere informazioni a più host contemporaneamente.
L’UDP è invece multicast.
Nella comunicazione di tipo multicast un insieme di processi formano un gruppo di multicast e un messaggio spedito da un processo a quel gruppo viene recapitato a tutti gli altri partecipanti appartenenti al gruppo.
Le API multicast devono contenere primitive per:
- unirsi a un gruppo (join)
- lasciare un gruppo (leave)
- spedire messaggi a un gruppo
- ricevere messaggi indirizzati a un gruppo del quale l’host fa parte.
La gestione dei gruppi è di tipo dinamico:
- un host può unirsi o abbandonare un gruppo in qualsiasi momento e può appartenere a più gruppi
- non è necessario appartenere a un gruppo per poter inviare a esso dei messaggi
- i membri del gruppo possono appartenere alla medesima rete o a reti fisiche differenti
Come indirizzo di multicast viene utilizzato un indirizzo IP di classe D, gli indirizzi possono essere:
- permanenti, l’indirizzo di multicast viene assegnato dalla IANA e rimane assegnato a quel gruppo anche se in un certo momento non ci sono più partecipanti
- temporanei, richiedono la definizione di un opportuno protocollo per evitare conflitti nell’attribuzione degli indirizzi ai gruppi ed esistono solo fino al momento in cui esiste almeno un partecipante.
La comunicazione multicast utilizza il paradigma connectionless dato che devono essere gestite contemporaneamente un alto numero di connessioni.
Esempio socket in Java
Stream socket
import java.io.IOException;
import java.net.InetAddress;
import java.net.Socket;
import java.net.ServerSocket;
public class StreamClient {
public StreamClient() throws IOException {
// Creo il socket connesso al server socket tramite IP e porta
Socket cs = new Socket(InetAddress.getLocalHost(), 1025);
// Invio "4" al server
cs.getOutputStream().write(4);
// Aspetto la risposta
int square = cs.getInputStream().read();
// Visualizzo la risposta
System.out.println(square);
// Chiudo il socket
cs.close();
}
}
public class StreamServer {
public StreamServer() throws IOException {
// Creo il socket per il server
ServerSocket ss = new ServerSocket(1025);
// Abilito le richieste
Socket ds = ss.accept();
// Aspetto una richiesta
int n = ds.getInputStream().read();
System.out.println("Richiesto il quadrato di " + n);
// Creo la risposta
int square = n*n;
// Invio la risposta
ds.getOutputStream().write(square);
// Chiudo il socket
ss.close();
}
}Datagram socket
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.nio.charset.StandardCharsets;
public class DatagramClient {
public DatagramClient() throws IOException {
// Creo il socket datagram
DatagramSocket ds = new DatagramSocket();
// Prendo in input da tastiera del testo
BufferedReader tastiera = new BufferedReader(new InputStreamReader(System.in));
String testo = tastiera.readLine();
// Creo il buffer con i byte del testo
byte[] buffer = testo.getBytes(StandardCharsets.UTF_8);
// Creo il pacchetto datagram
InetAddress indirizzoServer = InetAddress.getLocalHost();
DatagramPacket packet = new DatagramPacket(buffer, buffer.length, indirizzoServer, 1025);
// Invio il pacchetto
ds.send(packet);
// Preparo il pacchetto che dovrà contenere la risposta ricevuta dal server
byte[] bufferResponse = new byte[2048];
DatagramPacket response = new DatagramPacket(bufferResponse, bufferResponse.length);
// Aspetto la risposta
ds.receive(response);
// La visualizzo
System.out.println(new String(response.getData()).trim());
// Chiudo il socket
ds.close();
}
}
public class DatagramServer {
public DatagramServer() throws IOException {
// Creo il socket datagram
DatagramSocket ds = new DatagramSocket(1025);
// Creo il buffer ed il pacchetto datagram per la richiesta del client
byte[] buffer = new byte[2048];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
// Aspetto un pacchetto
ds.receive(packet);
// Estrapolo il messaggio
String messaggio = new String(packet.getData()).trim();
// Invio la risposta con il messaggio in UpperCase
String messaggioUppercase = messaggio.toUpperCase();
DatagramPacket response = new DatagramPacket(messaggioUppercase.getBytes(StandardCharsets.UTF_8), messaggio.length(), packet.getAddress(), packet.getPort());
ds.send(response);
// Chiudo il socket
ds.close();
}
}Esempio applicativo
Le applicazioni lato server
Oggi sono disponibili diverse tecniche di programmazione server-side.
Una prima classificazione può essere fatta in base alla “relazione” che questi programmi hanno con l’HTML:
- Codice separato, associato ad un URL:
- Common Gateway Interface (CGI)
- Java servlet
- NSAPI (o server API)
- Codice embedded in HTML:
- Server Side Includes - Apache
- PHP
- Java Server Pages (JSP)
Common Gateway Interface (CGI)
Viene invocata una procedura indicando l’indirizzo del programma CGI il quale viene eseguito sul server e al quale vengono inviati i parametri letti nel form html.
Le operazioni sono:
- Il client invia al server la richiesta di eseguire un programma CGI
- Il server chiama il programma indicato dal client passandogli i parametri letti nel form
- Il programma CGI esegue le operazioni e comunica al server la pagina HTML di risposta
- il server invia al client i dati elaborati
Per comunicare con l’utente il programma CGI produce una pagina HTML e la passa al Web server che la invia al client.
Servlet
La principale differenza tra servlet e CGI è che gli script CGI sono eseguiti dal sistema operativo e sono potenzialmente meno portatili delle servlet che vengono eseguite dalla JVM integrata nel Web server.
Gli script CGI inoltre vengono cariati ed eseguiti una volta per ogni richiesta, mentre le servlet vengono caricato solo una volta e viene creato un thread per ogni richiesta.
Il Web server stesso svolge la funzione di container occupandosi della gestione del ciclo di vita delle servlet.
Una servlet interagisce con un Web client attraverso il paradigma di comunicazione request/response.
Flusso di esecuzione:
- Un client invia una richiesta per una servlet a una Web application server
- Se si tratta di una prima richiesta allora il server carica la servlet
- Si attiva un thread che gestisce la comunicazione tra il client e la servlet
- Il server invia al thread-servlet la richiesta pervenutagli dal client
- Il thread-servlet costruisce e imposta la risposta e la inoltra al server
- Il server invia la risposta al client
Il servlet container più diffuso e utilizzato è tomcat.
Ciclo di vita di una servlet
init(): al momento del caricamento in memoria il container invoca il metodoinit()che inizializza la servlet e le variabili.
service(): questo metodo serve per ricevere e rispondere alle richieste dei client.
destroy(): per terminare l’esecuzione di una servlet viene invocato questo metodo, solitamente solo quando termina l’esecuzione del Web server.
Strutturazione delle directory:
- 📂 webapps → 📂 nome_progetto:
- file *.html, *.jsp, ecc.
- 📂 WEB-INF
- 📂 classes
- classi java compilate in file *.class
- 📂 lib
- eventuali file di libreria *.jar
- web.xml
- 📂 classes
Il file web.xml, chiamato anche Deployment descriptor, serve per configurare l’applicazione Web in modo che Tomcat possa gestire le richieste da parte dei client.
Vengono definiti:
- il nome della classe che definisce la servlet
- i percorsi che causano l’invocazione della servlet
- una serie di parametri di configurazione
Esempio web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app>
<servlet>
<servlet-name>NomeServlet</servlet-name>
<servlet-class>dev.giuliopime.NomeServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>NomeServlet</servlet-name>
<url-pattern>/percorso</url-pattern>
</servlet-mapping>
</web-app>Vantaggi delle servlet
- Efficienza: vengono caricate una sola volta.
- Portabilità: Java è facilmente portabile su ogni piattaforma
- Persistenza: quando una servlet viene caricata rimane in memoria
- Gestione delle sessioni: con le servlet è possibile memorizzare i dati delle sessioni
Svantaggi delle servlet
- Con le servlet si mescola la logica dell’applicazione con la presentazione
- A volte risulta difficoltoso dover inglobare all’interno del codice Java il codice HTML
- Ogni modifica del codice richiede una ricompilazione esplicita e il riavvio dell’applicazione o del server
Connessione a database tramite JDBC
JDBC racchiude una serie di classi per poter accedere alle basi di dati con metodi e schemi di funzionamento molto intuitivi.
JDBC è un’interfaccia, cioè uno “strato di programmazione” che si interpone tra il codice Java e i database.
Per prima cosa è necessario caricare il driver idoneo per l’utilizzo del particolare database che si intende utilizzare.
Come secondo passo si apre una connessione verso un database sfruttando il driver caricato:
jdbc:mysql://[hostname][:port]/[dbname]
Per interagire con il DBMS attraverso delle query viene creato un oggetto java.sql.Statement.
I risultati ottenuti vengono salvati in un oggetto di tipo ResultSet.
Oltre alla stringa di connessione dovremo fornire username e password per accedere al database.
JSP
La tecnologia JSP (Java Server Pages) è basata su Java e permette lo sviluppo di applicazioni web con contenuti dinamici senza dover essere legati a un ambiente in particolare. Una pagina JSP è rappresentata da codice HTML con incapsulate al suo interno delle direttive JSP, racchiuse in un particolare tag <%...%>, rappresentanti codice Java.
La programmazione di pagine JSP è una fusione tra la programmazione dinamica in linguaggio PHP e quella effettuata mediante la realizzazione delle servlet. Con la tecnologia JSP è possibile utilizzare strumenti come i JavaBean per spostare tutta la logica al loro interno in modo da ridurre al minimo l’utilizzo delle scriptlet <%...%>.
Web Service
Definizione
Un Web service è un componente applicativo largamente utilizzato. Possiamo definirlo come un sistema software in grado di mettersi al servizio di una applicazione comunicando su di una medesima rete tramite il protocollo HTTP. Un Web service consente quindi alle applicazioni che vi si vogliono collegare di usufruire delle funzioni che mette a disposizione. Questa tecnologia si basa su due caratteristiche fondamentali:
- multipiattaforma: client e server non devono avere le stesse configurazioni per comunicare fra di loro. Il servizio web fornisce quindi un terreno comune;
- condivisione: nella maggior parte dei casi, un servizio web non è disponibile solo per un unico client ma è progettato per avere l’accesso di più client contemporaneamente.
Un Web service viene indirizzato tramite un URI (Uniform Resource Identifier). Un aspetto importante è rappresentato dal linguaggio WSDL (Web Service Description Language). I servizi web dispongono di un file in WSDL che descrive il servizio in modo più dettagliato.
La comunicazione avviene attraverso diversi protocolli e architetture, come ad esempio SOAP o REST.
SOAP
SOAP (Simple Object Access Protocol) è un protocollo standard ideato inizialmente per consentire la comunicazione tra applicazioni realizzate con linguaggi e piattaforme diverse. Trattandosi di un protocollo, richiede l’integrazione di regole che ne aumentano la complessità e il carico di gestione sul sistema, comportando tempi di caricamento delle pagine più lunghi. Una richiesta di dati inviata a un API SOAP può essere gestita tramite uno dei protocolli a livello applicativo (HTTP, SMTP, TCP, ecc.) Una volta ricevuta la richiesta, i messaggi SOAP di ritorno devono essere restituiti come documenti in formato XML.
REST
REST (Representational State Transfer) è un insieme di principi architettonici incentrati sulle esigenze di ottimizzazione di servizi web e applicazioni mobili. Trattandosi sostanzialmente di linee guida o raccomandazioni, la loro implementazione è lasciata agli sviluppatori. In genere, una richiesta di dati inviata ad una API REST avviene tramite il protocollo HTTP. Una volta ricevuta la richiesta, le API progettate per REST (chiamate API o servizi web RESTful) possono restituire i messaggi in numerosi formati: HTML, XML, testo semplice o JSON.