Sistemi e Reti
VLAN
Lo standard 802.1Q definisce le specifiche che permettono di definire più reti locali virtuali (VLAN) distinte, utilizzando una stessa infrastruttura fisica.
Ciascuna VLAN si comporta come se fosse una rete locale separata dalle altre:
- I pacchetti broadcast sono confinati all’interno della VLAN
- La comunicazione a livello 2 è confinata all’interno della VLAN
- La connettività tra diverse VLAN può essere realizzata solo a livello 3, attraverso routing.
Scopo
L’utilizzo delle Virtual Lan permette di realizzare:
- Risparmio: non è necessario realizzare una nuova infrastruttura di rete locale con apparti e linee dedicate per creare una nuova LAN parallela entro lo stesso ambiente della LAN preesistente;
- Aumento di prestazioni: il confinamento del traffico broadcast permette di evitare la propagazione di frame verso destinazioni che non hanno necessità di riceverlo;
- Aumento della sicurezza: una utenza connessa ad una VLAN non ha modo di vedere il traffico interno alle altre VLAN
- Flessibilità: lo spostamento fisico di una utenza all’interno dei locali raggiunti dalla infrastruttura di rete può essere realizzato senza modifiche della topologia fisica, ma logicamente attraverso l’opportuna riconfigurazione degli apparati di rete.
Requisiti
Per realizzare una VLAN è necessario che gli switch di rete siano capaci di distinguere le diverse VLAN.
Gli apparati devono osservare lo standard 802.1Q
Vi sono diversi modi per realizzare una VLAN:
- Port based (o private VLAN);
- Tagged (802.1Q).
In ogni caso dentro lo switch devono essere definite le VLAN, con nome e numero identificativo per distinguerle una dall’altra.
Funzioni dello Switch in 802.1Q
Esistono tre funzioni che gli switch devono saper svolgere:
- Ingress: lo switch deve essere in grado di capire a quale VLAN appartiene un frame in ingresso.
- Forwarding: lo switch deve conoscere verso quale porta inoltrare il frame, in funzione della VLAN di appartenenza.
- Egress: lo switch deve poter trasmettere il frame in uscita in modo che la sua appartenenza alla VLAN venga correttamente interpretata da altri switch.
Port based VLAN (Untagged)
Prevede l’assegnazione statica di ciascuna porta ad una VLAN.
Porte diverse possono essere assegnate a VLAN differenti.
Di fatto in questo modo si partiziona uno switch in due o più switch logici.
Le VLAN untagget non richiedono l’osservanza dello standard 802.1Q, ma solo che lo switch ne supporti la configurabilità.
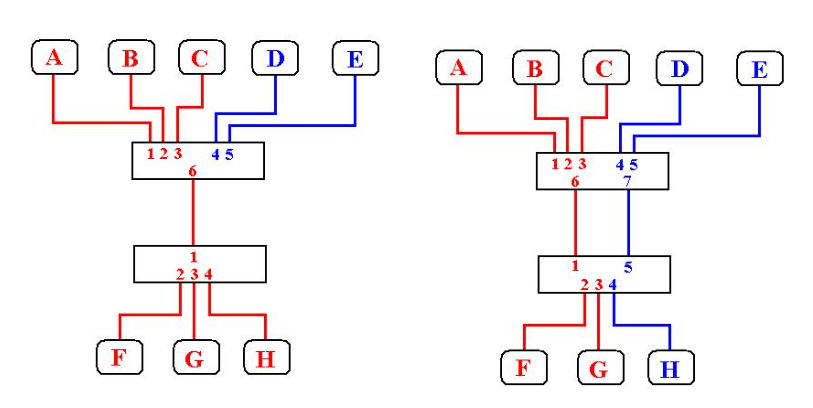
VLAN 802.1Q (Tagged)
Lo standard viene utilizzato per poter condividere lo stesso link fisico tra VLAN differenti.
Per poter fare ciò lo switch deve poter distinguere la VLAN di appartenenza del frame in arrivo.
Lo standard definisce una modifica del formato del frame ethernet aggiungendo 4 byte che trasportano le informazioni sulla VLAN.
Poiché tutti gli switch devono concordare sulla VLAN di appartenenza di un frame, l’identificativo (VLAN tag) della VLAN deve essere uguale per tutti gli switch.
Il formato del frame Ethernet secondo lo standard 802.1Q contiene due campi aggiuntivi:
- TPI (Tag Protocol Identifier): due bytes di valore 81 00 che identificano il frame come 802.1Q.
- TCI (Tag Control Information): due bytes che trasportano le informazioni sulla tag:
- I primi tre bit indicano l’eventuale livello di priorità del frame
- Il quarto bit (CFI) vale 1 se il frame proviene da una LAN token ring
- I restanti 12 bit (VID) trasportano la VLAN tag (da 0 a 4095)

Il campo TPI ha un valore che non è utilizzato come protocol type nei frame Ethernet ordinari, questo permette di identificare immediatamente se un frame è di tipo 802.1Q e una scheda Ethernet non conforme a questo standard scarterebbe il frame.
Il frame così costituito rappresenta una violazione dello standard Ethernet poiché eccede la dimensione massima e tutti gli switch che osservano questo standard devono poter accettare frame con 2 byte in più.
Porte Tagged ed Untagged
In uno switch 802.1Q tutte le porte devono essere associate ad una o più VLAN.
Se la porta è associata ad una VLAN “port based” (untagged) i frame ricevuti da quella porta non trasporteranno TAG, né dovranno trasportala i frame in uscita
In caso contrario la porta sarà associata ad una o più VLAN in modalità Tagged, ed i frame trasporteranno le informazioni di tag
La VLAN di appartenenza del frame è definito dal valore inserito nella TAG.
Porte ibride
Lo standard richiede che una porta possa essere associata ad una VLAN in modalità untagged e ad altre VLAN in modalità tagged.
Se non ha la TAG il frame appartiene alla VLAN a cui la porta è associata in modalità untagged
Se ha la TAG la VLAN è definita dal valore di tale TAG.
La VLAN a cui la porta è associata in modalità untagged viene anche detta PVID (Private Vlan ID).
Funzioni in 802.1Q
- Ingress: quando viene ricevuto un frame lo switch deve identificare la VLAN di appartenenza:
- Se il frame è untagged la VLAN è identificata con la VLAN a cui la porta è associata
Se il link è di tipo trunk il frame viene scartato.
- Se il frame è tagged, la VLAN viene identificata dalla TAG.
Se il link è access, o la porta non è associata in modalità tagged alla VLAN indicata nella TAG, il frame viene scartato.
- Se il frame è untagged la VLAN è identificata con la VLAN a cui la porta è associata
- Forwarding: una volta identificata la VLAN di appartenenza vengono applicate le regole di forwarding e viene identificata la porta di uscita
- La, o le, porte in uscita devono essere associate alla VLAN di appartenenza del frame.
- Egress: questa funzione può richiedere la modifica del frame ricevuto:
- Se il frame in ingresso è 802.1Q e la porta in uscita è associata alla VLAN di appartenenza in modalità tagged, il frame non subisce modifiche;
- Se il frame in ingresso è untagged e la porta in uscita è associata alla VLAN di appartenenza in modalità untagged, il frame non subisce modifiche;
- Se il frame in ingresso è 802.1Q e la porta di uscita è untagged, la TAG viene rimossa;
- Se il frame in ingresso è 802.3 e la porta di uscita è tagged, la TAG viene inserita.
Negli ultimi due casi lo switch deve ricalcolare il valore del CRC.
Coesistenza con apparati non 802.1Q
Gli apparati che non osservano lo standard 802.1Q saranno connessi su porte dello switch associate esclusivamente in modalità untagged.
Questo garantisce che ogni frame ricevuto sarà associato ad UNA VLAN e nessun frame di tipo 802.1Q sarà inoltrato verso l’apparato, in quanto la TAG deve essere rimossa.
Questo permette di inserire in una rete locale apparati 802.1Q senza dover sostituire l’hardware preesistente.
Nell’esempio il link tra i due switch è di tipo trunk e trasporta frame di entrambe le VLAN. Gli switch devono inserire la tag per trasmettere i frame verso l’altro switch. Gli switch dovranno rimuovere la tag prima di inoltrare i frame verso la stazione di destinazione.
Nessun frame appartenente ad una VLAN può raggiungere stazioni connesse su porte associate ad un’altra VLAN.
Per realizzare una comunicazione tra stazioni appartenenti a VLAN differenti i dati devono essere inoltrati a livello di rete da un router.
Protocol based VLAN
L’assegnazione di un frame ad una VLAN può essere effettuata dinamicamente, in funzione di diversi parametri.
Le regole di assegnazione devono essere configurate negli switch opportunamente, non tutti gli switch 802.1Q sono in grado di effettuare l’assegnazione dinamica.
I parametri possono essere:
- Indirizzo IP del mittente
- Protocol type del frame Ethernet
- Indirizzo Ethernet della stazione mittente.
Un esempio tipico è la assegnazione definita dal MAC address: nessuna stazione può accedere ad una VLAN se il suo MAC non è registrato dall’amministratore della rete, indipendentemente dalla porta a cui si connette.
Default VLAN
Gli switch 802.1Q vengono venduti con una VLAN predefinita, detta default VLAN.
Alla default VLAN è assegnata la TAG 1.
Tutte le porte appartengono alla default VLAN in modalità untagged (PVID = 1)
Poichè una porta non può essere associata a più di una VLAN in modalità untagged, per modificare il PVID di una porta si deve prima rimuovere l’associazione della porta in modalità untagged preesistente.
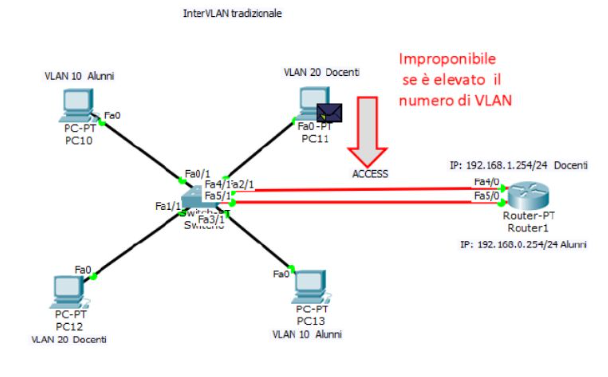
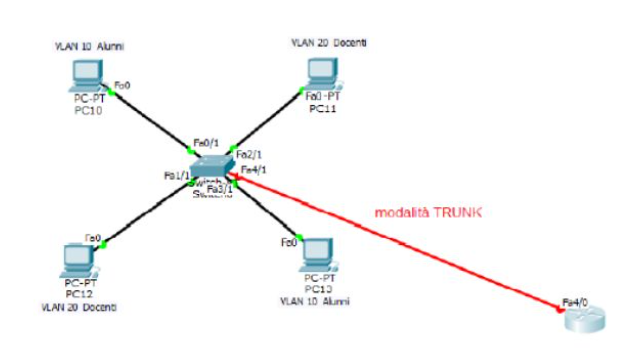
Esempi di comunicazione tra VLAN con router
VLAN - Trunking Protocol (VTP)
La configurazione delle VLAN deve essere effettuata per ogni switch presente nella rete LAN.
Nel caso di LAN di dimensioni elevate:
- Complessità di gestione;
- Possibilità di errori nella configurazione.
Il protocollo Vlan Trunking Protocol (VTP) consente di configurare le VLAN su solo uno switch, che si occupa poi di distribuire le VLAN a tutti gli switch della rete.
Il protocollo VTP riduce la configurazione manuale degli switch.
Nel VTP troviamo:
- VTP domain;
- VTP Server;
- VTP Client;
- VTP Transparent;
- VTP Advertisement;
- Trunk.
Il comando che consente di valutare la configurazione VTP di uno switch è
Switch# show vtp status
I parametri da configurare sono:
- VTP version;
- VTP domain;
- VTP mode;
- Config Revision;
- VLANs.
VTP Version - VTP mode
Esistono due versioni del protocollo VTP: 1, 2.
La versione di default è la 1.
Il parametro VTP mode può assumere tre diversi valori, a seconda del ruolo dello switch:
- Server
- Client
- Transparent
Di default lo switch lavora come Server.
Vtp Domain Name
E’ il nome del dominio VTP cui lo switch appartiene, un VTP domain è un insieme di switch che si scambiano VTP advertisement per la distribuzione delle VLAN.
Uno switch può possedere un solo dominio VTP alla volta.
Il dominio si propaga dal VTP server a tutti i VTP client.
Di default è Null.VTP Advertisement
Un messaggio VTP è inviato ogni qual volta bisogna propagare le VLAN.
Esistono tre tipi di Advertisement:
- Summary: contengono il VTP Domain Name ed il Config Revision. Sono inviate ogni 5 minuti ed hanno lo scopo di informare i vicini del corrente VTP Config Revision. Vengono inviati anche subito dopo una modifica.
- Subset: contengono informazioni sulle VLAN (inserimento, cancellazione, modifica).
- Request: inviate ad un VTP server per richiedere l’invio di un messaggio Summary e di eventuali messaggi subset.
VTP Config Revision
E’ un contatore che viene incrementato ogni volta che si verifica una modifica relativa al VTP: Vlan aggiunta o rimossa.
Inizialmente è impostato a zero.
Consente agli switch di determinare se le informazioni memorizzate sono aggiornate o meno.
Configurazione VTP Server
// Configurare la modalità server e il VTP Domain Name
Switch(config)# vtp mode server
Switch(config)# vtp domain nome
//Controllare ed eventualmente configurare la versione del protocollo VTP e la password
Switch(config)# vtp version
//configurare le VLAN (E le porte TRUNK)
Switch(config)# show vtp statu
//Verificare che lo switch abbia la configurazione di default
// abilitare modalità Client
Switch(config)# vtp mode client
//configurare le porte di access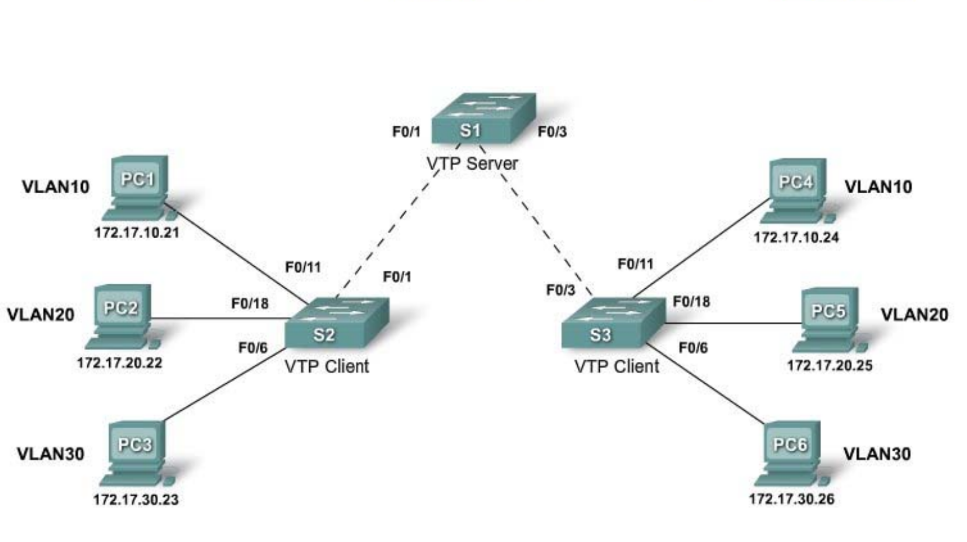
Tecniche di crittografia
La crittografia è nota fin dall’antichità e si è sviluppata nel corso del tempo, soprattutto in ambito militare.
La codifica e la decodifica sono eseguite da uno o più algoritmi crittografici, che utilizzano:
- Una o più funzioni matematiche;
- Una o più chiavi per operazioni di cifratura e decifratura.
Elementi di crittografia
- Crittografia: procedimento di cifratura e decifratura dei messaggi basato su funzioni parametriche;
- Testo in chiaro: messaggio originario;
- Algoritmo di cifratura: effettua sostituzioni e trasformazioni sul testo in chiaro;
- Algoritmo di decifratura: effettua il lavoro inverso dell’algoritmo di cifratura;
- Chiave: parametro dell’algoritmo di cifratura o decifratura.
Classificazione dei sistemi crittografici
I sistemi crittografici possono essere distinti in base a:
- Tipo di operazioni usate per trasformare il testo in chiaro in testo cifrato:
- Sostituzione: ogni elemento del testo in chiaro è trasformato in un altro elemento;
- Trasposizione: gli elementi del testo in chiaro sono riorganizzati.
- Numero di chiavi (distinte) utilizzate:
- Chiave singola: crittografia a chiave simmetrica (o chiave segreta), le chiavi del mittente e del destinatario sono identiche;
- Due chiavi: crittografia a chiave asimmetrica (o a chiave pubblica), la chiave di cifratura è pubblica, la chiave di decifratura è privata.
- Il modo in cui il testo in chiaro è elaborato:
- Cifrario a blocchi: elabora in blocchi di dimensioni fissa;
- Cifrario a flusso: elabora senza una lunghezza predefinita.
Cifrari a sostituzione
Le tecniche di sostituzione sostituiscono le lettere del testo in chiaro con altre lettere (o numeri, simboli, ecc..).
Una della più semplici e famose è la cifratura di Cesare.
Cifrari a trasposizione
Le lettere del testo in chiaro non cambiano (come nella sostituzione) ma ne viene alterata la posizione.
Il testo cifrato è quindi una permutazione del testo in chiaro.
La chiave è la permutazione stessa, un attacco a forza bruta dovrebbe quindi tentare tutte le permutazioni possibili (ovvero n!, n lunghezza del messaggio).
Crittoanalisi
Opposte alla crittografia si sono sviluppate tecniche di crittoanalisi con lo scopo di analizzare e cercare di violare le comunicazioni cifrate: ovvero decifrare il testo senza conoscere la chiave.
Esistono due modi:
- Attacchi a forza bruta: si prova ogni chiave possibile, fino a trovare quella corretta.
- Analisi crittografica: si sfruttano informazioni sull’algoritmo, le caratteristiche dei testi in chiaro o l’analisi di coppie note di testi in chiaro/testo cifrato.
Un sistema di cifratura è computazionalmente sicuro se il testo cifrato soddisfa uno dei seguenti criteri:
- Il costo per rendere inefficace il cifrario supera il valore dell’informazioni cifrata;
- Il tempo richiesto per rendere inefficace il cifrario supera l’arco temporale in cui l’informazione è utile.
Esistono due tipi di sicurezza:
- Sicurezza incondizionata: è impossibile decifrare il testo senza sapere la chiave, indipendentemente dal tempo e dalla quantità di dati disponibili;
- Sicurezza computazionale: come abbiamo visto prima,
- Il costo della violazione supera il valore delle informazioni crittografate;
- Il tempo di violazione supera la vita utile delle informazioni crittografate.
Esistono due tipi principali di crittografia:
- Simmetrica
- Asimmetrica
Crittografia simmetrica
Usa una sola chiave per cifrare e decifrare, mittente e destinatario usano la stessa chiave.
Esiste però il problema della distribuzione delle chiavi.
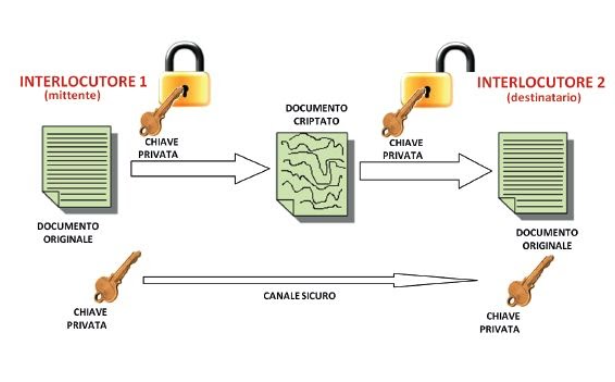
Un esempio di crittografia simmetrica è il doppio operatore XOR.
Svantaggi 👎🏼
- Difficoltà nel mantenere la chiave K segreta;
- La segretezza dipende dai possessori di K;
- Per N conoscenti bisognerebbe avere N chiavi distinte;
- Difficoltà per la distribuzione sicura della chiave K, ovvero dello scambio.
La crittografia Asimmetrica
Nasce nel 1975 ed è chiamata anche “crittografia a chiave pubblica”.
Risolve il problema della distribuzione sicura delle chiavi poichè utilizza una coppia di chiavi.
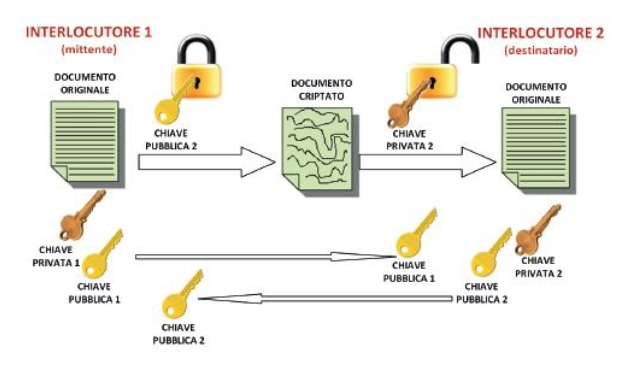
Le due chiavi sono correlate MATEMATICAMENTE: i messaggi codificati con la chiave pubblica possono essere decodificati solo con la chiave privata e viceversa.
Anche conoscendo la chiave pubblica non è possibile risalire alla corrispondente chiave private se non con calcoli che richiedono un tempo molto elevato.
La coppia di chiavi viene generata da un software.
Ogni persona che vuole ricevere i messaggi cifrati deve fornirsi di una coppia di chiavi:
- La chiave privata mantenuta segreta;
- La chiave pubblica viene distribuita liberamente a tutte le persone con cui si vuole comunicare.
I mittenti devono così conoscere solamente la chiave pubblica del destinatario e la chiave privata è conservata solamente dal destinatario, risolvendo il problema dello scambio delle chiavi.
Firma digitale
Essa consente di garantire la certezza che quel documento appartiene al firmatario. Il documento in formato digitale sottoscritto con firma digitale ha perfetta validità legale.
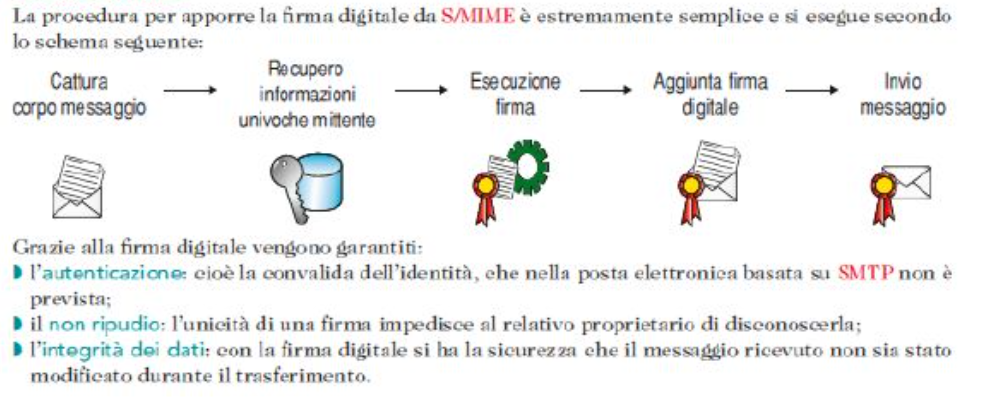
La firma digitale garantisce:
- Integrità: assicura che il documento digitale non abbia subito modifiche successive alla sottoscrizione;
- Autenticità: garantisce l’identità del firmatario;
- Non ripudio: impedisce al sottoscrittore di negare la paternità del documento, dato che la firma gli attribuisce piena validità legale.
Per generare una firma digitale è necessario utilizzare una coppia di chiavi digitali asimmetriche attribuite in maniera univoca ad un soggetto detto titolare.
La chiave privata è conosciuta solo dal titolare ed è usata per generare la firma digitale da apporre al documento.
Viceversa la chiave da rendere pubblica è usata per verificare l’autenticità della firma.
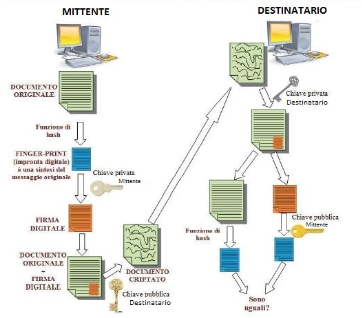
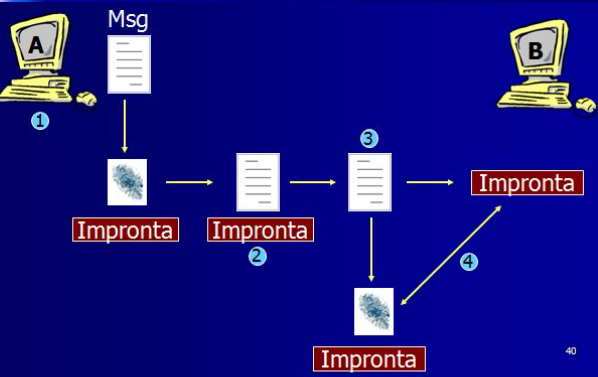
Hash: letteralmente significa sminuzzare. E’ un algoritmo che restituisce una sequenza di lunghezza ben definita avendo come input un messaggio di lunghezza qualsiasi
Finger-print: letteralmente significa impronta digitale. E’ un documento prodotto dall’algoritmo di hash a partire da quello originale. Documenti diversi elaborati dall’algoritmo di hash producono una finger-print diversa.
- Il primo passo consiste nel generare, con l’hash, un “riassunto” del documento originale. La modifica al contenuto del messaggio porta ad avere una diversa impronta - digitale.
- L’impronta digitale viene crittografata con la chiave privata del mittente, ottenendo la “firma digitale”.
- La firma digitale viene allegata al documento originale, il messaggio completo può essere inviato al destinatario dopo averlo crittografato con la chiave pubblica del destinatario.
- Il destinatario decripta il messaggio ottenendo il documento orginale e la firma.
- Il destinatario, utilizzando la chiave pubblica del mittente, ricava la finger - print.
- A questo punto sarà sufficiente confrontare questo finger-print con quello che egli calcolerà in modo autonomo.
Se i due finger print corrispondono egli sarà sicuro che:
- Il messaggio è integro.
- Chi ha spedito il messaggio è veramente chi dice di essere;
- Il mittente non può ripudiare il messaggio.
Firmare un documento elettronico è un’attività semplice e veloce, per eseguirla è necessario essere dotati di:
- Dispositivo di generazioni delle firme (smart cad o pen drive);
- Lettore di smart card/pen drive;
- Software di verifica e firma.
Certificati
Il certificato di sottoscrizione rappresenta l’elemento chiave della firma digitale; non è altro che un file rilasciato dall’ente certificatore contenente tutti i dati identificativi del titolare.
L’impiego della firma digitale permette di migliorare i rapporti tra Pubbliche Amministrazioni, cittadini e imprese, riducendo notevolmente la gestione in forma cartacea dei documenti, proprio come indicato da AGID (Agenzia per l’Italia Digitale).
L’agenzia si occupa di:
- Offrire l’elenco di certificatori accreditati a cui si può richiedere la firma digitale;
- Sottoscrivere una lista dei certificati delle chiavi di certificazione;
- Definire le linee guide per la vigilanza sui gestori qualificati;
- Autorizza i certificatori a svolgere la propria attività conferendogli il ruolo di “Certificatori accreditati”;
- effettua vigilanza sui certificatori accreditati.
Esiste però la problematica di “mascheramento”, ovvero: siamo certi noi che il certificato che riceviamo sia effettivamente del mittente? e non sia di qualcuno che si “maschera” come tale?
La soluzione di questo problema viene fatta attivando una particolare procedura per la consegna della chiave pubblica: la chiave viene racchiusa all’interno di un certificato digitale che oltre a essa contiene le informazioni sul mittente.
Questo certificato deve essere a sua volta validato da un ente certificatore (CA, Certification Autorithy) che garantisce l’identità del proprietario del certificato firmandone le chiavi pubblica e privata con la propria chiave privata: in questo modo ne rende impossibile per chiunque la manomissione.
Quindi il certificato digitale è un documento informatico contenuto nella smartcard del titolare e firmato digitalmente dal certificatore. I dati contenuti nel certificato sono:
- Dati del proprietario e la chiave pubblica;
- Dati del certificato, tra cui la data di scadenza;
- Dati della CA.
Un malintenzionato dovrebbe effettuare le seguenti operazinoi per sostituirsi all’effettivo mittente:
- Violare la cifratura del CA che protegge le due chiavi;
- Sostituire le chiavi originale con delle chiavi fasulle;
- Ricodificare il tutto con la chiave privata della CA.
Le pratiche relative alla identificazione dell’utente prima della emissione del certificato vengono fatte dalla Registration Authority che, in base alla tipologia del soggetto, svolge le necessarie indagini e attiva le relative procedure per l’identificazione certa del richiedente.
Registration Authority e Certification Authority sono enti pubblici o privati accreditati.
Un certificato digitale può avere diversi formati:
- Chiavi PGP/GPG;
- Certificati X.509;
Richiedere un certificato digitale
- Generazione della coppia di chiavi asimmetriche da utilizzare per cifrare le comunicazioni: le comunicazioni tra CA e richiedente devono essere protette e quindi viene generata una coppia di chiavi dal CA;
- Il richiedente comunica informazioni circa la propria identità al CA;
- La Registration Authority inizia la verifica dei dati ricevuti;
- Se i controlli vanno a buon fine, la Certification Authority genera il certificato e lo firma digitalmente con la propria chiave privata: viene firmato perchè i dati contenuti non vengano modificati.
- Il certificato firmato viene inviato al richiedente che provvederà a installarlo sul proprio server.
Esistono numerosi programmi che consentono di criptare file:
Gestione file:
- Kleopatra: unisce alla crittografia la gestione dei certificati;
- FileVault: crea file auto-estraenti e auto-decifranti.
Disco fisso:
- VeraCrypt: crea dischi fissi cifrati.
Dati:
- Data Scramble: trasforma i dati in un’immagine bitmap con algoritmo MD5.
Algoritmi di cifratura
→ DES
1977 → Reso pubblico
1998 → Viene rotto
Tipologia (Simmetrico & A Blocchi)
- Simmetrico: cifratura e decifrazione con la stessa chiave
- A blocchi: messaggio suddiviso in blocchi cifrati indipendentemente
Proprietà
- Diffusione: altera la struttura del testo in chiaro spargendo i caratteri su tutto il testo cifrato
- Confusione: combinare in modo complesso il messaggio e la chiave
Algoritmo
3-DES
Introdotto → 1999
Consiste in 3 passi di cifratura DES consecutivi con chiavi diverse, per un totale di 168 bit di chiave (56 x 3, le chiavi sono da 64 bit ma ne hanno 8 di parità).
In ordine avviene: cifratura → decifrazione → cifratura (per la codifica) decifrazione → cifratura → decifrazione (per la decodifica)
3 varianti a seconda delle chiavi
- tre chiavi diverse
- k1 e k3 uguali: sicurezza di 112 bit
- tre chiavi uguali: usata per garantire la compatibilità con il DES standard (sicurezza 56 bit)
→ IDEA
IDEA utilizza chiavi da 128 bit che al primo passo vengono suddivide in 8 blocchi da 16 bit ciascuno.
Le prime 6 chiavi generate vengono utilizzate direttamente nel primo passo dell’algoritmo; nei passi successivi invece la chiave usata al passo precedente viene shiftata ciclicamente di 25 posizioni a sinistra, per poi essere suddivisa nuovamente in 8 blocchi da 16 bit.
Nell’ultimo passo vengono utilizzati soltanto i primi 4 blocchi ottenuti dalla chiave shiftata.
Il messaggio da cifrare viene suddiviso in blocchi da 64 bit e, ad ogni passo, il blocco da 64 bit viene suddiviso in 4 blocchi da 16 bit, chiamati A, B, C, D:
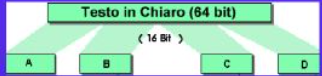
Ad ogni passo i (1≤ i ≤ 8), avvengono le seguenti operazioni:

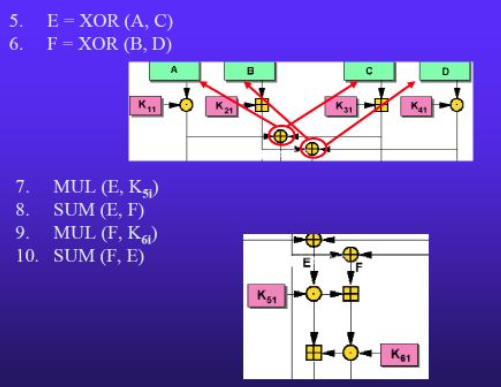
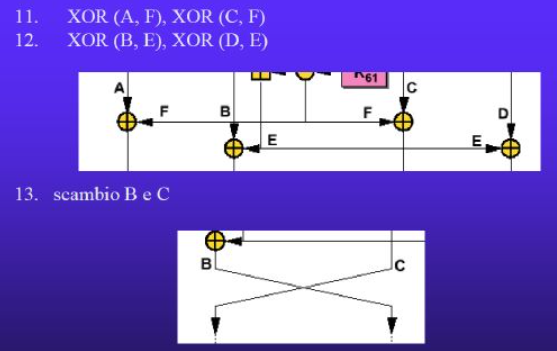
I passaggi visti fino ad ora vengono eseguiti 8 volte.
Arrivati all’ultimo round, il 9°, vengono eseguiti meno passaggi:

Una volta arrivati al 9° round l’algoritmo è terminato e basterà unire G1, G2, G3, G4 per ottenere il testo cifrato da inviare.
Lo schema completo di IDEA è il seguente:
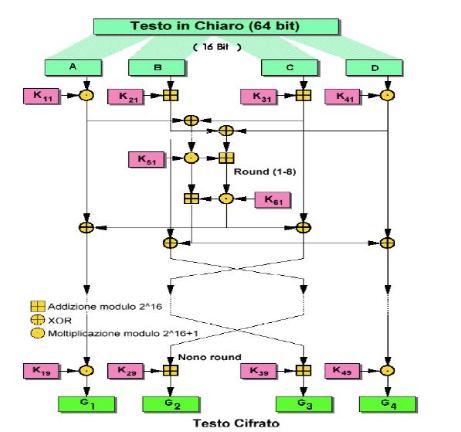
Decifrazione
La decifrazione del messaggio segue lo stesso identico schema, ma le chiavi utilizzate sono invertite rispetto a MUL e ADD.
Vantaggi
- La forza di IDEA sta nella segretezza della chiave e che si ha un range di possibili chiavi pari a 2^128.
- L’algoritmo è abbastanza facile da applicare ed è molto veloce; si potrebbe anche rendere più veloce eseguendo solamente 4 round al posto di 9, dato che è stato dimostrato che diventa impossibile da forzare dopo il quarto passo.
- Può essere implementato sia via software che hardware, con semplici componenti che lavorano a 16 bit.
→ RSA
E’ un algoritmo di cifratura Asimmetrico.
E’ composto da:
- Chiave pubblica di 2 numeri → K (pub) = (pub, n);
- Chiave privata di 2 numeri → K (pri) = (pri, n);
Per cifrare un messaggio:
c = m^pub mod n
dove m è un carattere o un blocco del messaggio trasformato in binario
Per decifrare un messaggio:
m = c^pri mod n
Come si ricavano le chiavi K(pub) e K(pri)?
- Sceglio due numeri primi a e b molto grandi e calcolo
n = a * b → secondo numero delle chiavi
- Determino z = (a-1)*(b-1)
e sceglo le chiavi:
- Pri → non deve avere fattori comuni con z;
- Pub → deve soddisfare l’equazione (pub*pri) mod z = 1
→ Diffie - Hellman
Prendiamo in esempio Alice e Bob, entrambi conoscono due numeri, g e p pubblici e p è un numero primo.
Inoltre Alice conosce un numero segreto ‘a’ e Bob conosce un numero segreto ‘b’.
→ Alice calcola A = g^a mod p e lo comunica a Bob;
→ Bob calcola B = g^b mod p e lo comunica ad Alice;
→ Alice calcola K = B^a mod p = [g^b mod p]^a mod p = g^ab mod p;
→ Bob calcola K = A^b mod p = [g^a mod p]^b mod p = g^ab mod p;
Così facendo Alice e Bob hanno condiviso un numero segreto (K) senza mai comunicarlo esplicitamente.
Chiunque può osservare A, B, g ep ma queste informazioni non sono sufficienti per ricavare il numero K.
Infatti K è calcolabile solo conoscendo a o b, che tuttavia sono segreti e non vengono mai comunicati.
Ricavare a da A (o b da B) significa risolvere un logaritmo discreto, il che è computazionalmente difficile.
Se questo numero K rappresenta la chiave di un algoritmo di cifratura simmetrica si è trovato un modo per condividere la chiave senza la necessità di un canale di comunicazione sicuro.
Il problema però è che Alice e Bob non hanno potuto scegliere il valore di tale numero, ma è casuale.
Perciò l’algoritmo di Diffie - Hellman non è un algoritmo di crittografia ma è esclusivamente un algoritmo di scambio delle chiavi.
→ Crittografia Ibrida
Essendo che:
- Cifrari Simmetrici sono veloci ma hanno un numero di chiavi molto elevato (e considerato anche il problema dello scambio sicuro delle chiavi).
- Cifrari Asimmetrici sono lenti ma più efficienti.
Allora si è pensato all’utilizzo di un cifrario ibrido:
→ Cifrario Simmetrico per la comunicazione;
→ Cifrario Asimmetrico per lo scambio di chiavi k.
In particolare:
Il destinatario, tramite la sua chiave privata, decifra la chiave simmetrica utilizzata per codificare il messaggio.
Tramite questa chiave decodificata, decodifica il messaggio stesso.
→ AES
Advanced Encryption Standard
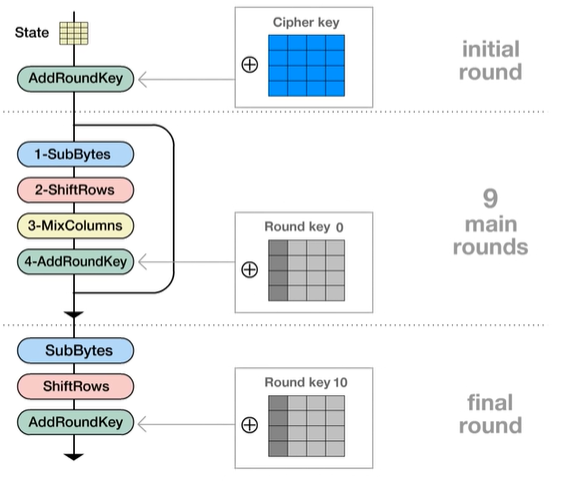
L’AES è un cifrario a blocchi.
Utilizza blocchi da 128 bit e può usare chiavi da 128, 192 e 256 bit.
La lunghezza della chiave influisce sulla schedulazione delle chiavi e sul numero di round, però non influisce sulla struttura di alto livello di ciascun round.
I 128 bit vengono divisi in 16 byte, per poi essere sistemati all’interno di una tabella 4x4, così come la chiave:
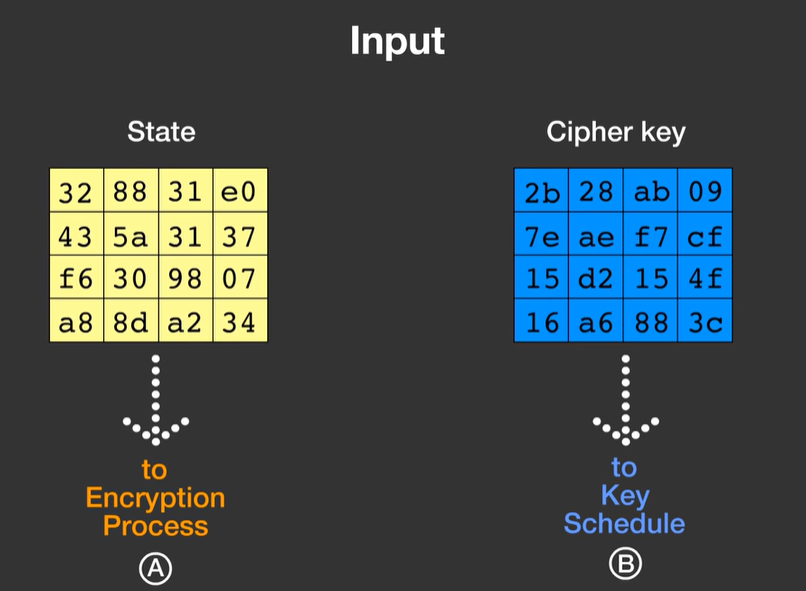
A - processo di cifratura
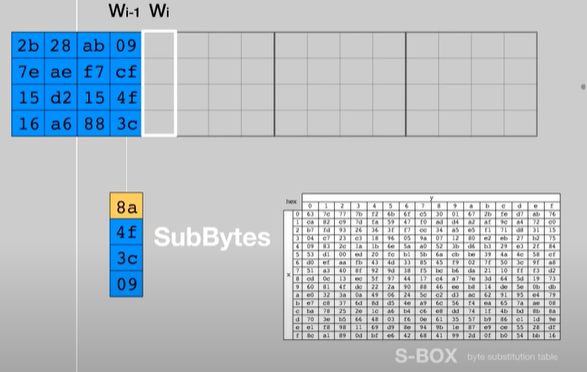
1- SubBytes: è una funzione SBOX nella quale tramite righe e colonne il valore iniziale di una cella (ad esempio cella 1,1 contenente il valore 19) viene alterato.
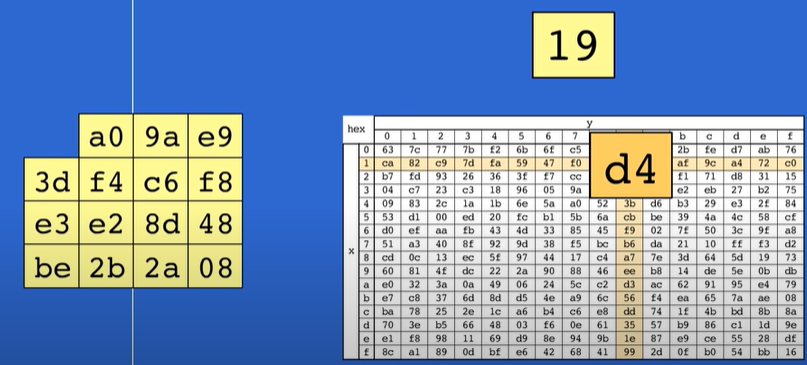
Così per ogni byte all’interno della tabella 4x4.
2- ShiftRows: la seconda riga della tabella viene shiftata verso sinistra di 1 byte, la terza riga di 2 bytes e la quarta riga di 3 bytes.
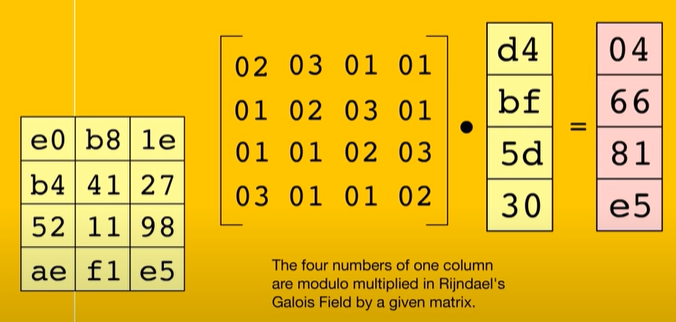
3- MixColumns: ogni cella di ogni colonna viene “modulo moltiplicata” con una matrice predefinita:
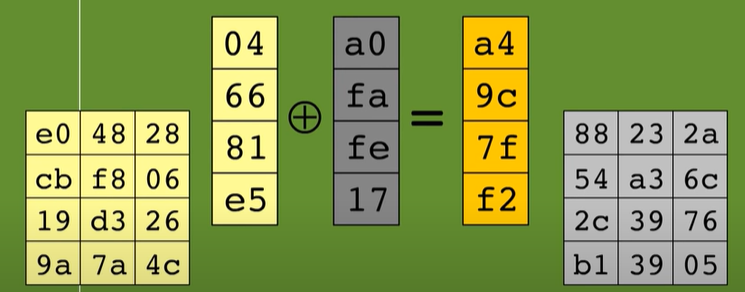
4- AddRoundKey: viene eseguito lo XOR tra ogni colonna della tabella 4x4 ottenuta dai tre passaggi precedenti e ogni colonna della tabella 4x4 contenente la chiave:
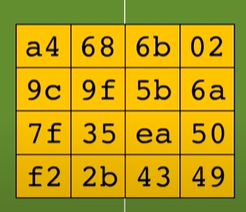
Così da ottenere:
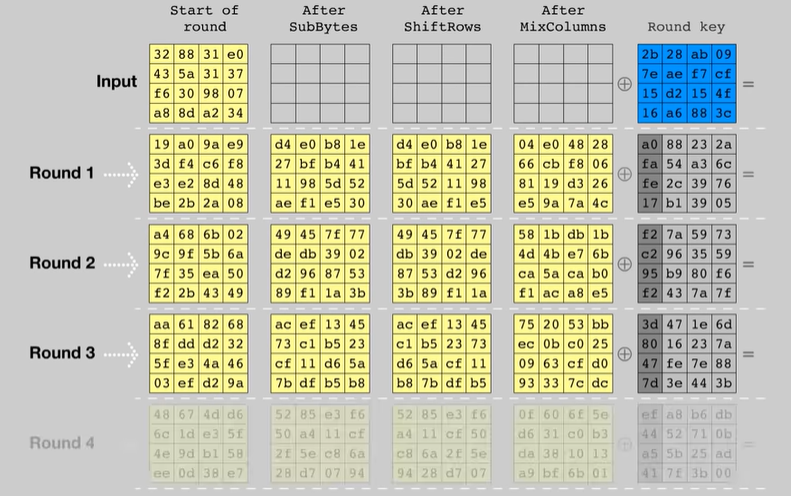
Queste trasformazioni vengono eseguite per 9 round consecutivi, l’ultimo round, quello finale, non include il MixColumns.

B - Key Schedule
La chiave viene divisa in 11 sotto - chiavi usate nel round iniziale, nei 9 round centrali e nel round finale.
La chiave può essere vista come un array di 32-bit words (colonne) numerate da 0 fino a 43, dove le prime 4 sono riempite con la chiave ricevuta.

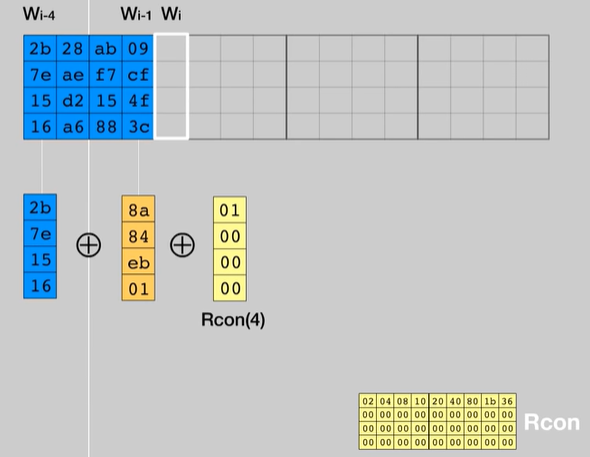
Le colonne multipli di 4 (W4, W8, …, W40), quindi le prime di ogni tabella, sono calcolate applicato RotWord e SubBytes (visto prima) alla colonna precedente:
RotWord consiste nello spostare il primo byte da sopra a sotto.
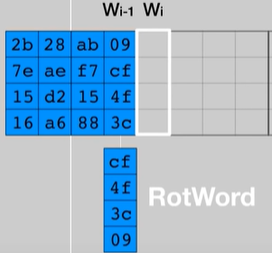
Successivamente viene effettuato uno XOR tra il risultato ottenuto dalla SBOX e la “word” situata in 4 posizioni prima e una costante chiamata Rcon.
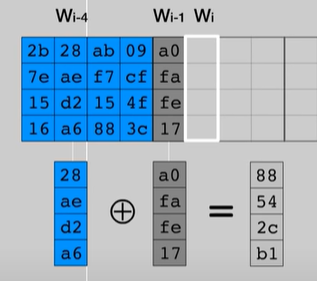
Per quanto riguarda le restanti colonne invece basterà calcolare tramite uno XOR il risultato tra la colonna precedente e quella posizionata in 4 posizioni prima.
Le funzioni HASH
Per soddisfare le condizioni di sicurezza, gli algoritmi per le funzioni hash devono seguire queste proprietà:
- Devono essere coerenti → a input uguali corrispondono output uguali;
- Devono essere casuali → impedire l’interpretazione accidentale del messaggio originale;
- Devono essere univoci → la probabilità che due messaggi diversi generino lo stesso hash deve essere virtualmente nulla;
- Devono essere non invertibili → non deve essere possibile risalire al messaggio originale dall’output.
Le funzioni hash non invertibili vengono normalmente utilizzate per assegnare un’impronta digitale a un messaggio o a un file.
Le funzioni hash non invertibili vengono utilizzate per accertarsi che nessuno in fase di trasporto sia intervenuto sul contenuto del messaggio.
Il problema in questo caso è che non c’è modo di proteggere l’impronta da eventuali intrusi.
E’ possibile infatti che qualcuno interferisca impersonando il mittente o il destinatario nelle comunicazioni sicure.
Perciò le funzioni hash vanno combinate con sistemi a chiave pubblica per l’assegnazione di firme digitali.
Tra le funzioni hash più comuni troviamo:
→ L’algoritmo MD4 (Message digest 4);
→ L’algoritmo MD5 (Message digest 5);
→ L’algoritmo SHA (Secure Hash Algorithm).
Gli attuali prodotti per la sicurezza utilizzano principalmente algoritmi MD5 e SHA, entrambi basati sul sistema MD4.
MD5 elabora l’input a blocchi da 512 bit e produce un output (digest) da 128. SHA elabora blocchi da 512 bit e produce un digest da 160 bit.
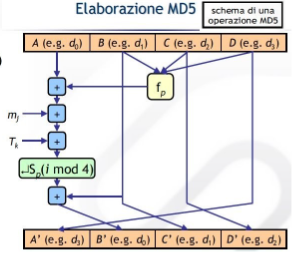
→ MD5
Il messaggio viene elaborato a blocchi di 512 bit e viene prodotto un hash da 128 bit.
Ad ogni iterazione si calcola una funzione che prende in ingresso il blocco corrente del messaggio e il valore dell’hash all’iterazione precedente.
L’hash finale è quello risultante dall’ultima iterazione.
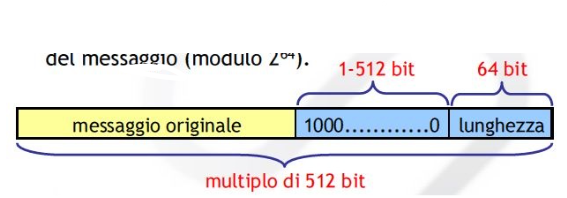
Prima di iniziare l’elaborazione si aggiunge al messaggio un padding in modo che la lunghezza totale risulti un multiplo di 512 bit.
In particolare:
→ Si aggiunge un bit a 1 e poi tanti 0 affinchè la lunghezza risulti di 64 bit minore rispetto ad un multiplo di 512.
→ Gli ultimi 64 bit contengono la lunghezza originale del messaggio.
Un’iterazione MD5 è composta da 4 passi, perciò ogni blocco del messaggio viene elaborato in 4 “round” successivi.
La funzione utilizzata dipende dal round:
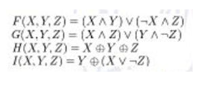
In ogni round la funzione di compressione viene applicata 16 volte.
→ SHA
L’elaborazione eseguita dagli algoritmi SHA è simile a quella MD5, è costituita da quattro fasi: le prime due sono identiche mentre la terza utilizza uno schema a 8 registri (al posto di 4) e nel passo 4 la sequenza di bit viene divisa in blocchi da 512 bit o 1024, a seconda dell’algoritmo.
La sicurezza delle reti
La sicurezza dei sistemi informativi mira a proteggere le informazioni dalle minacce di tipo umane e naturali.
Le minacce di tipo umane possono essere indotte da interessi personali e possono essere attacchi interni o esterni.
Gli attacchi interni possono essere condotti da dipendenti o ex dipendenti che conoscono la struttura.
Le minacce naturali sono dovute a eventi naturali tipo innondazione, incendi, terremoti, ecc..
Per evitare si eseguono misure preventive come il posizionamento dei dati in locali adeguati.
Tra gli eventi intenzionali, ovvero gli attacchi troviamo:
→ Ip spoofing / Shadow server: qualcuno si sostituisce ad un host;
→ Packet sniffing: si leggono password di accesso o dati riservati;
→ Connection hijacking: si inseriscono o modificano i dati durante il loro transito in rete;
→ Denial of service (DoS) e Distributed DoS (DDoS): si impedisce il funzionamento di un servizio.
Tra gli eventi accidentali, cioè gli errori e i malfunzionamenti, individuiamo:
→ Non adeguatezza degli strumenti;
→ Locale server sensibile alle innondazioni;
→ Errata gestione delle password;
→ Ecc..
Le principali tipologie di minacce sono:
- Attacchi passivi;
- Attacchi attivi.
Attacchi passivi
Tra gli attacchi passivi troviamo:
→ Lettura del contenuto, ad esempio medianto lo sniffing di pacchetti;
→ Analisi del sistema e del traffico di rete, senza analizzare i contenuti.
Attacchi attivi
Tra gli attacchi attivi troviamo:
→ Intercettazione: mira a intercettare le password per avere accesso al sistema;
→ Sostituzione di un host: qualcuno si sostituisce ad un host falsificando l’indirizzo di rete;
→ Ping flooding;
→ SYN attack;
→ Distributed Denial of Service (DDoS);
→ Phishing: attraverso spamming di email si attrae un utente su un server pirata;
→ Intrusione: accesso non autorizzato a uno o più host.
E’ necessario perciò introdurre delle misure di sicurezza per proteggere sia le informazioni presenti sugli host sia quelle circolanti sulla rete.
Bisogna però effettuare una distinzione tra:
- Sicurezza nella rete;
- Sicurezza sugli host:
- A livello di sistema operativo
- A livello di applicazione
I tre “pilastri” della sicurezza sono:
- Prevenzione: mediante protezione dei sistemi e delle comunicazioni;
- Rilevazione: mediante il monitoraggio e il controllo degli accessi
- Investigazione: con l’analisi dei dati, il controllo interno, ecc..
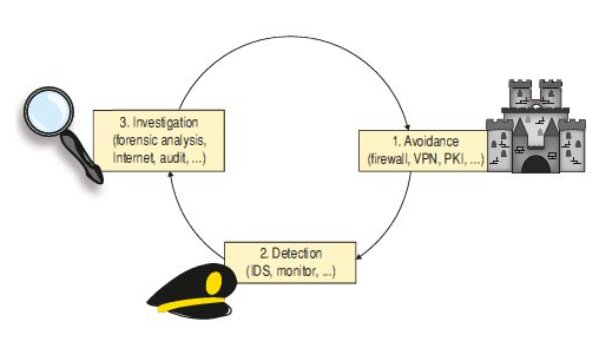
Per quanto riguarda la prevenzione troviamo diverse tecniche, come:
→ Uso della crittografia;
→ Autenticazione degli utenti, nel dettaglio troviamo:
- Identificazione: risponde alla domanda “Chi sei?”
- Autenticazione: risponde alla domanda “Come mi accerto che sei tu?”
- Autorizzazione: risponde alla domanda “Cosa posso fare?”
→ Firma elettronica;
→ Connessioni TCP sicure mediante SSL;
→ Firewall.
→ Reti private e reti private virtuali (VPN).
La sicurezza per i messaggi di posta elettronica
La posta elettronica è il servizio di internet più importante dati che è utilizzato praticamente da tutti coloro che hanno un account.
La posta è lo strumento preferenziale per sferrare attacchi sulla rete dato che il protocollo SMTP non offre alcuna garanzia di riservatezza.
Una email può essere esposta ad attacchi mentre “sosta” in buffer temporanei presso switch, router, gateway e host intermedi.
Le specifiche originarie del protocollo SMTP non prevedono nessuna forma di autenticazione.
Nei protocolli POP3 e IMAP che, al contrario di SMTP, prevedono una forma di autenticazione, la comunicazione avviene in chiaro, per cui i pacchetti spediti possono essere intercettati su uno qualsiasi dei computer attraversati. In questo modo è possibile scoprire perfino la stessa password.
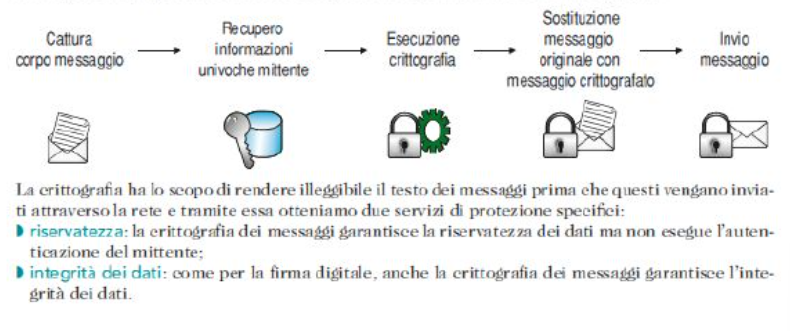
La sola cifratura non garantisce una sicurezza adeguata per i messaggi che transitano su internet.
I problemi di sicurezza della posta elettronica sono materialmente difficili da risolvere, si può peroò ridurre il problema usando connessioni protette tramite SMTP + SSL e POP + SSL e utilizzando tecniche di sicurezza fornite da PGP e da S/MIME.
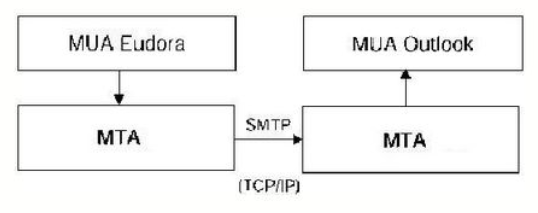
La posta elettronica viene implementata attraverso la cooperazione di due tipi di sottosistemi:
- Mail User Agent (MUA);
- Mail Transport Agent (MTA).
MUA
E’ l’interfaccia con il client, è un programma di gestione di posta (Outlook) operativo sul client, che deve:
→ Possedere un’interfaccia utente per l’inserimento, la composizione, la ricezione e la lettura dei messaggi;
→ Conoscere il protocollo per spedire i messaggi (SMTP);
→ Conoscere il protocollo POP3 e IMAP4;
→ Conoscere la sintassi di composizione dei messaggi.
MTA
Funge da ponte tra due MUA, è l’interfaccia con la rete e quindi si iccupa della ricezione e trasmissione dei messaggi.
L’MTA può essere:
→ Un server SMTP che gestisce la spedizione e la ricezione dei messaggi verso e da altri server SMTP;
→ Un server POP3 che gestisce la spedizione dei messaggi al client;
→ Un server IMAP4 che permette la gestione dei messaggi sul server dal client.
Gli obiettivi di una posta sicura sono:
- Integrità: il messaggio non può essere modificato;
- Autenticazione: identifica il mittente;
- Non ripudio: il mittente non può negare di aver spedito la mail;
- Riservatezza: i messaggi non siano leggibili agli intrusi.
Il protocollo S/MIME
Il protocollo SMTP presenta un limite dal punto di vista della protezione e una sua alternativa è il protocollo S/MIME che fornisce due servizi di protezione:
- Firme digitali;
- Crittografia dei messaggi.
Questi due servizi sono alla base della protezione dei messaggi S/MIME in quanto un messaggio può essere firmato, cifrato oppure essere sottoposto a entrambi.
Firme digitali
Crittografia dei messaggi
Interazione delle firme digitali con la crittografia dei messaggi
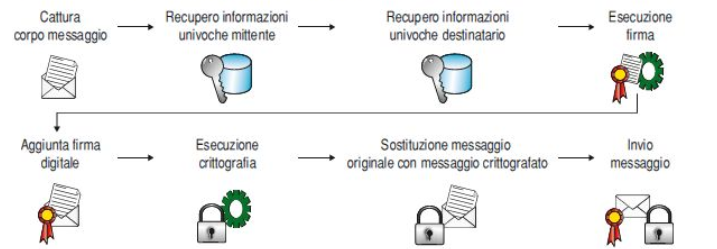
Invece per decifrare un messaggio bisognerà:
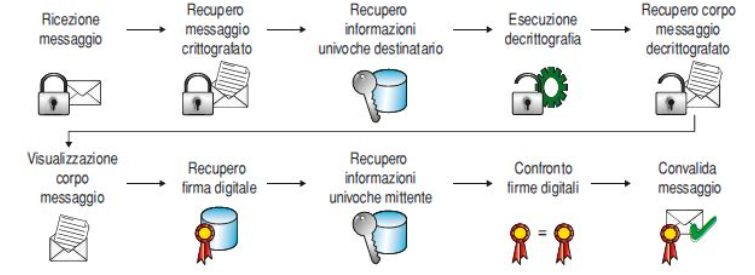
PGP
Pretty Good Privacy è uno dei più celebri software per la crittografia a chiave pubblica utilizzato soprattuttop er codificare le email.
Obiettivo principale del PGP è quello di aumentare la rapidità della codifica RSA.
Con PGP per procedere al criptaggio di un messaggio la prima operazione da effettuare è quella di generare una session key: generata in modo estremamente casuale e verrà usata una sola volta per cifrare il messaggio.
Quindi questa viene criptata con la chiave pubblica del destinatario e inviata insieme al messaggio.
Perciò, riassumendo:
- Mittente genera una chiave;
- Mittente si procura la chiave pubblica RSA del destinatario;
- Mittente utilizza tale chiave per codificare la chiave generata randomicamente;
- Mittente cifra il messaggio attraverso l’uso dell’algoritmo simmetrico IDEA.
Il destinatario, una volta ricevuto il messaggio, per prima cosa decripta la chiave randomica (session key) e lo fa utilizzando la propria chiave privata.
Una volta decriptata la utilizza per decifrare il messaggio ricevuto.
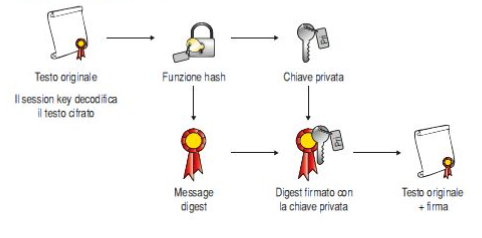
Firma con message digest
PGP migliora il sistema di firma aggiungendo una funzione hash unidirezionale che prende in input il messaggio di lunghezza variabile e genera un output di lunghezza prefissata.
Il digest e la chiave privata sono utilizzati da PGP per creare la “firma” che viene spedita insieme la testo.
Alla ricezione del messaggio PGP ricalcola il digest e lo confronta con quello ricevuto in modo da verificare la correttezza della firma.
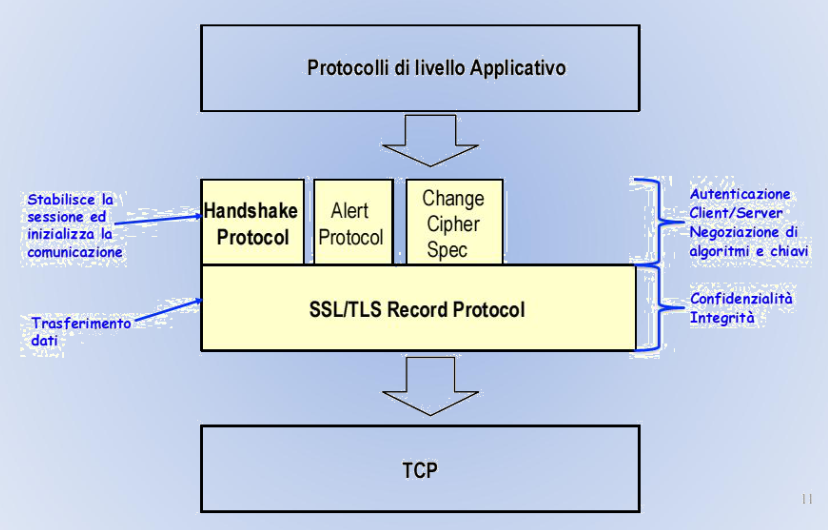
I protocolli SSL / TLS
Secure Socket Layer e Transport Layer Security.
Offrono meccanismi di sicurezza alle applicazioni che usano il protocollo TCP e sono in grado di rendere sicuri numerosi protocolli applicativi come HTTP, POP3, IMAP, ecc..
TLS e SSL lavorano a livello transport della pila ISO/OSI si interpongono tra il livello application e il protocollo TCP.
TCP/IP consente di leggere ed alterare i dati che vengono inviati in rete.
Caratteristiche
→ Fornisce l’autenticazione per applicazioni server e client;
→ Cifra i dati prima di inviarli su un canale pubblico;
→ Garantisce l’integrità dell’informazione;
→ E’ stato progettato per essere efficiente.
Componenti
→ Handshake Protocol:
Permette alle parti di negoziare i diversi algoritmi necessari per la sicurezza delle transazioni e consente l’eventuale autenticazione tra le parti.
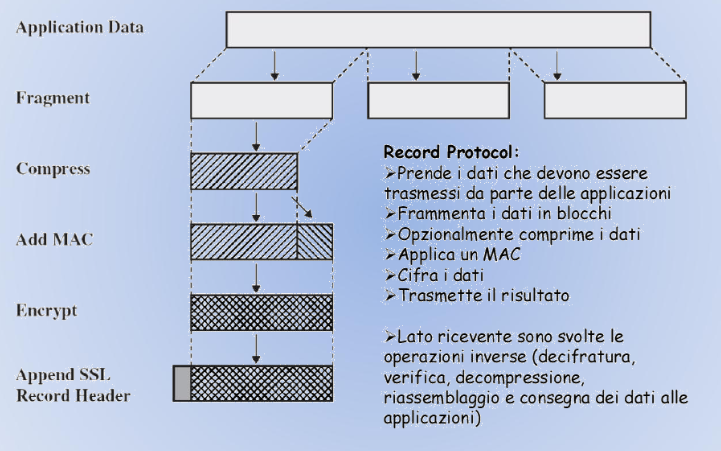
→ Record Protocol:
Si occupa della compressione, del MAC e della cifratura.
→ Change Chiper Spec Protocol:
Impone l’esecuzione di un nuovo handshake per rinegoziare i parametri di sicurezza e ripetere l’autenticazione.
→ Alert Protocol:
Notifica situazioni anomale o segnala eventuali problemi.
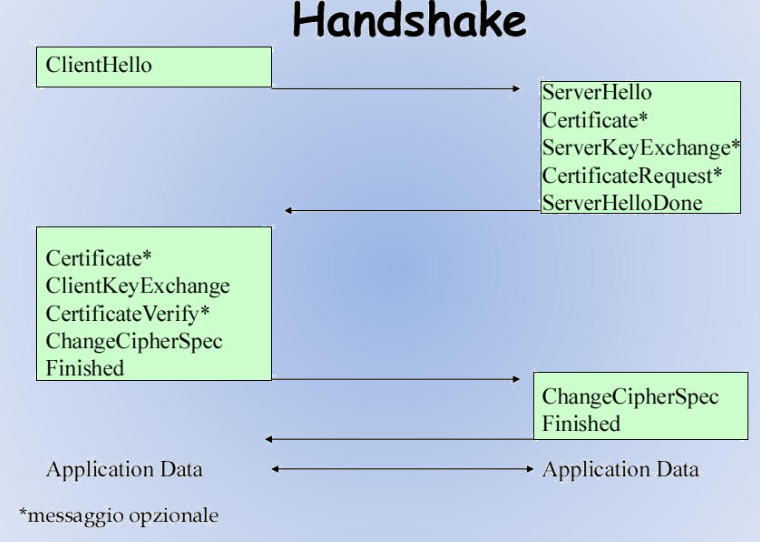
Handshake Protocol
E’ utilizzato dalle due parti (client e server) e permette di:
→ Negoziare la versione del protocollo e l’insieme degli algoritmi crittografici da utilizzare (ciperhsuite).
→ Stabilire le chiavi crittografiche da utilizzare.
→ Autenticare client e server (opzionale): utilizzo di certificati digitiali per ottenere la chiave pubblica dell’altro endpoint e verificarne l’identità.
Ciperhsuite
Gli algoritmi crittografici usati da SSL/TLS dipendono dalla ciperhsuite su cui si sono accordate le parti.
La ciperhsuite e gli algoritmi di compressione sono negoziati mediante l’handshake.
Una ciperhsuite definisce:
→ Funzione hash usata dall’HMAC (es. SHA).
→ Schema di cifratura simmetrica (es. 3DES) → Sia block cipher che stream cipher.
→ Schema per l’accordo e lo scambio di chiavi (es. RSA oppure DH).
Sessione sicura
Una sessione sicura rappresenta una sequenza di valori che possono essere utilizzati con SSL/TLS:
→ Valori segreti calcolati durante l’handshake;
→ Ciperhsuite stabilita durante l’handshake.
Stabilire tutti i parametri ogni volta che c’è una connessione può essere inefficiente, perciò una sessione può sopravvivere tra più connessioni.
Costo di una Sessione
Lato client:
→ Generazione di valori random; → Verifica del certificato del server; → Generazione valori random per la chiave;
→ Calcolo della chiave attraverso hash.
Lato server:
→ Generazione di valori random;
→ Decifrazione valori inviati dal client;
→ Verifica del certificato del client;
→ Calcolo della chiave attraverso gli hash.
Informazioni di Stato relativi a Sessione e Connessione
Sessione:
→ Session ID;
→ Certificati;
→ Algoritmo di compressione e ciperhsuite;
→ Master key: per la derivazione delle varie chiavi utilizzate dal protocollo;
→ Riesumabile: valore booleano che indica se la sessione può essere utilizzata in più connessioni.
Connessione:
→ Numeri di sequenza;
→ Chiavi MAC;
→ Chiavi di cifratura;
→ Vettori di inizializzazione (IV);
Chiavi ed IV sono creati in base alla Master Key.
Il protocollo di Handshake può essere eseguito in forma abbreviata, per riesumare una sessione precedentemente stabilita.
Autenticazione: Certificate, Certificate {Request, Verify}
Sono i messaggi che consentono alle parti di autenticarsi.
Il messaggio Certificate contiene una lista di certificati:
→ Il certificato del server deve essere conforme all’algoritmo di autenticazione specificato nella ciperhsuite.
→ Il certificato del client deve essere inviato solo se c’è un messaggio Certificate Request.
L’eventuale certificato del client deve essere conforme alle specifiche indicate nel messaggio di richiesta.
L’invio dei certificati non è obbligatorio ma quello del server può essere necessario.
Certificate Verify
Il messaggio Certificate Verify viene inviato dal client solo se quest’ultimo ha inviato il proprio certificato al server.
{Client, Server}Key Exchange
Il server invia il messaggio Server Key Exchange se il proprio certificatao non è adeguato al tipo di autenticazione stabilito nella chipersuite.
Il messaggio Client Key Exchange è obbligatorio. Con esso le parti hanno le informazioni necessarie per poter calcolare la chiave di cifratura simmetrica da utilizzare in seguito all’handshake
Il messaggio Server Key Exchange viene usato con il messaggio Finished per l’identificazione del server.
Change Cipher Spec - Finished
Mediante il messaggio Change Cipher Spec ogni parte indica all’altra che sta per usare gli algoritmi e le chiavi appena negoziate.
I messaggi Finished sono di testing, sono i primi messaggi che vengono inviati utilizzando algoritmi e chiavi negoziate durante le fasi precedenti.
Record Protocol
Change Cipher Spec Protocol
E’ utilizzato per aggiornare la ciphersuite in uso tra client e server.
Il protocollo consiste in un unico messaggio, inviato da una delle due parti all’altra; il messaggio è dato da un singolo byte di valore 1.
Alert Protocol
Usato da una parte per trasmettere messaggi di alert all’altra.
Ciascun messaggio è caratterizzato da un livello di severità: warning o fatal.
I messaggi possono essere tipo: unexpected message, handshake failure, unsupported certificate, …
Firewall
Firewall Hardware: componente passivo che opera una difesa perimetrale della nostra rete locale (LAN).
Firewall Softwate (o Personal Firewall): software che viene installato direttamente sul PC da proteggere. Il personal firewall esegue anche un controllo a livello di programma. (Monitorizza l’attività di scambio dati da e verso internet di tutto il software).
I limiti di un firewall
Ci sono due tipologie di problemi di sicurezza:
→ Configurazioni non corrette: attraverso una configurazione apposita si sarebbero potuti evitare incidenti.
→ Problematiche tecniche: nonostante una buona configurazione firewall, è possibile accedere ad un componente che si riteneva protetto sfruttando errori di programmazione o vulnerabilità del firewall.
Cosa non può fare un firewall?
→ Protezione da attacchi interni:
Una volta che il “muro” del firewall è stato oltrepassato, questo non è più di alcuna utilità. Infatti ci offre una protezione perimetrale e tutto ciò che è interno all’area è escluso dal filtraggio.
→ Social Engineering:
Usato per indicare coloro che telefonano agli impiegati spacciandosi per membri della sicurezza per estorcere informazioni.
→ Integrità dei dati:
E’ impensabile chiedere ai firewall in reti di grandi dimensioni di controllare tutti i pacchetti alla ricerca di virus. La soluzione sarebbe applicare un antivirus in tutte le macchine.
→ Cattiva configurazione:
Non è in grado di distinguere da solo ciò che va bloccato e ciò che va accettato. Quindi la qualità del firewall dipende dalla qualità della configurazione.
Classificazione dei firewall
Una prima classificazione viene fatta sul tipo di protezione che il firewall deve fare:
→ Ingress firewall: vengono controllati i collegamenti incoming (in arrivo).
→ Egress firewall: vengono controllati i collegamenti outgoing (uscenti), cioè l’attività del personale all’interno della LAN verso l’esterno.
Una seconda classificazione si basa sul numero di host protetti contemporaneamente:
→ Pesonal Firewall: proteggono il singolo host consentendo, generalmente di default, qualsiasi traffico verso l’esterno e bloccando quello in ingresso.
→ Network firewall: si interpone fra la LAN e internet e controlla tutto il traffico passante.
La terza classificazione viene fatta secondo il livello di intervento:
→ Filtri di pacchetti IP: permettono di bloccare o abilitare selettivamente il traffico che attraversa il firewall, definendo i protocolli, gli indirizzi IP e le porte utilizzate.
→ Server proxy: rappresentano una sorta di intermediario che si occupa di intrattenere le connessioni per conto di qualcun altro nella rete interna.
Personal firewall
Può essere semplicemente un programma installato sul proprio PC che protegge da attacchi esterni: il traffico dall’interno verso l’esterno è consentito per default mentre il traffico dall’esterno verso l’interno è vietato per default.
Sono utilizzabili solo a scopo personale ma impensabili in una azienda in quanto risulterebbero economicamente non convenienti.
Network firewall
Sono i classici firewall aziendali dove una o più macchine sono dedicate al filtraggio di tutto il traffico da e per una rete locale.
A seconda del livello di rete nel quali si fanno i controlli i firewall possono essere classificati in:
- Packet filtering router: network level gateway;
- Stateful inspection: gateway a livello di trasporto;
- Proxy server: gateway a livello di applicazione.
Packet filtering router
Scherma i pacchetti dipendentemente dal protocollo, dall’indirizzo della sorgente e della destinazione e dai campi di controllo presenti nei pacchetti in transito, cioè analizza le informazioni contenute nell’header TCP/IP per individuare:
→ IP del mittente o del destinatario;
→ Indirizzo MAC sorgente o destinatario;
→ Numero di porta verso cui è destinato il pacchetto;
→ Protocollo da utilizzare.
Il firewall decide se il pacchetto può essere accettato o meno attraverso un algoritmo di scelta che si basa su una lista di regole precedentemente definite:
→ Ciò che NON è specificatamente permesso è proibito (deny).
→ Ciò che NON è specificatamente probiti è permesso (permit).
In base a queste regole i pacchetti possono essere:
→ Accept/allow: il firewall permette al pacchetto di raggiungere la sua destinazione.
→ Deny: il firewall scarta il pacchetto senza che questo passi attraverso il firewall.
→ Discart/reject: il firewall scarta il pacchetto senza restituire nessun messaggio d’errore all’host sorgente, implementando il cosiddetto blach hole, che elimina il pacchetto senza che la sua presenza venga rivelata agli estranei.
Vantaggi
- Trasparenza: l’utente non si accorge della presenza del firewall.
- Velocità: effettuando minori controlli rispetto agli altri firewall risulta essere il più veloce.
- Immediatezza: tramite la definizione di una singola regola si può difendere un’intera rete.
- Gateway-only: non sono richieste ulteriori configurazioni aggiuntive per i client.
- Topologia della rete interna invisibile dall’esterno: se viene aggiunto un NAT, dall’esterno l’unico host visibile è il gateway.
Svantaggi
- Basso livello: è veloce ma non è in grado di elaborare le informazioni dei livelli superiori a quello di rete e quindi non è in grado di bloccare attacchi mirati a vulnerabilità di una specifica appliazione.
- Mancanza di servizi aggiuntivi: non permettono la gestione di servizi come l’autenticazione, il filtraggio URL e dei contenuti delle pagine Web.
- Logging limitato: i file di log contengono poche informazioni che generalmente sono insufficienti per verificare se il firewall compie sempre il proprio dovere.
- Vulnerabile allo spooing: dato che vengono filtrari i pacchetti in base alla loro provenienza, i casi di IP spooing non vengono riconosciuti.
- Testing complesso: è lungo e complicato effettuare le prove che verifichino il funzionamento.
Stateful inspection
Anche detti firewall di seconda generazione, effettuano il filtraggio non sul singolo pacchetto ma sulla connessione.
Alla richiesta di connessione, se questa viene accettata, vengono memorizzate le sue caratteristiche in una tabella di stato in modo che i successivi pacchetti non vengano più analizzati ma gli venga permesso il transito, risparmiando al firewall notevoli quantità di elaborazione.
Nella tabella di stato per ogni connessione sono memorizzati:
→ Identificatore univoco del collegamento;
→ Indirizzi IP sorgente e destinazione;
→ Interfacce di rete utilizzate;
→ Stato della connessione:
- Handshaking se si è nella fase iniziale;
- Established se la connessione è stata stabilita;
- Closing se la connessione è terminata e si sta per eliminare la entry.
Vantaggi
- Buon rapporto prestazioni/sicurezza: offre un ottimo compromesso fra le prestazioni e la sicurezza dato che effettua meno controlli durante la connessione.
- Protezione da IP spooing e session hijacking: è molto più difficile riuscire a violare il firewall.
- Tutti i vantaggi del packet filtering router.
Svantaggi
- Protocollo unico: sfruttando molte delle caratteristiche del protocollo TCP risulta difficilmente utilizzata all’interno di altre infrastrutture di rete;
- Servizio di auditing limitato: le informazioni che registra nei file di log sono ancora insufficienti.
- Mancanza di servizi aggiuntivi: non permette servizi aggiuntivi come la gestione delle autenticazioni e il filtraggio dei contenuti.
- Testing complesso: è lungo e complicato effettuare le prove che verifichino il funzionamento.
Proxy server
Applica una politica di sicurezza molto più severa di un packet filtering router.
Viene installato un programma mirato sul gateway per ogni applicazione desiderata.
Se l’amministratore di rete non installa il programma proxy per una determinata applicazione, il servizio non è supportato e non può essere inoltrato attraverso il firewall.
Il proxy è un programma che viene eseguito sul gateway che funge da intermediario a livello di applicazione.
Nelle applicazioni client - server un application proxy comunica con il client simulando di essere il server, e viceversa, con il server simulando di essere il client.
Vantaggi
- Controllo completo: non fa verifiche solo alle informazioni contenute nell’header del pacchetto ma usa anche quelle contenute nel body.
- Log dettagliati: le informazioni memorizzate sono molto accurate.
- Nessuna connessione diretta: ogni volta i pacchetti in entrata e uscita vengono totalmente rigenerati.
- Sicurezza anche in caso di crash: un crash di un packet filtering router permetterebbe a qualunque pacchetto di viaggiare indisturbato, mentre un crash del proxy bloccherebbe completamente la connessione.
- Supporto per connessioni multiple: può capire se connessioni separate appartengono alla stessa applicazione.
- User - friendly: regole di filtraggio molto più facili da configurare rispetto a quelle di un packet filtering.
- Autenticazione e filtraggio contenuti: supportano un’autenticazione rigida dell’utente.
Svantaggi
- Costo.
- Difficoltà di amministrazione.
- Poco trasparente: i computer interni devono essere configurati per utilizzare il proxy invece di collegarmi direttamente al server.
- Un proxy per ogni applicazione: per ogni servizio che si vuole fare passare attraverso il firewall c’è bisogno di un proxy dedicato.
- Basse performance: richiede molto lavoro per la cpu.
Bastion host
Indichiamo l’host configurato per respingere attacchi contro la rete interna e più in generale tutti quegli host che fungono da firewall critici per la sicurezza della rete.
Possiede in genere le seguenti caratteristiche:
- Unico calcolatore della rete interna raggiungibile da internet;
- Dotato di software strettamente necessario, il più possibile privo di bug utilizzabili come vie d’accesso.
- File System a sola lettura.
- Numero minimo dei servizi e nessun account utente.
- Eliminazione dei servizi non fidati.
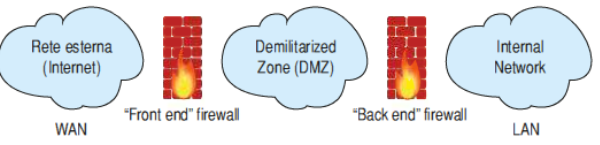
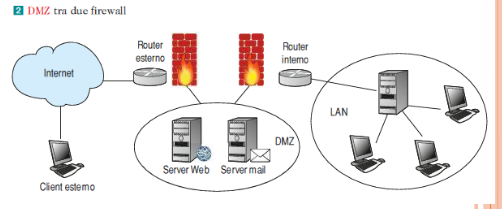
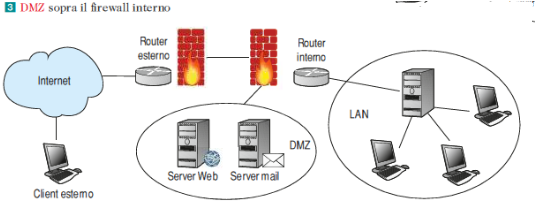
DMZ
E’ la sigla di Demilitarized Zone ed è una “sezione di rete”.
La zona demilitarizzata è una porzione di rete che separa la rete interna dalla rete esterna: i server nella DMZ sono accessibili dalla rete pubblica, perciò non sono trusted dalla rete interna, e quindi devono essere segregati, in quanto, se venissero compromessi, questo non deve produrre effetti nella rete aziendale.
La DMZ permette di effettuare la sicurezza perimetrale, cioè protegge una rete nei punti in cui essa è a contatto con il mondo esterno, interponendosi tra la LAN aziendale e la WAN esterna.
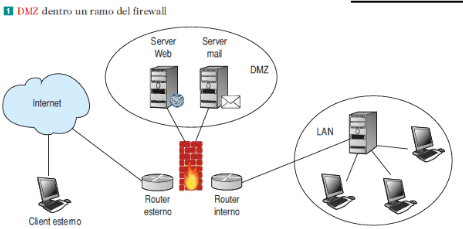
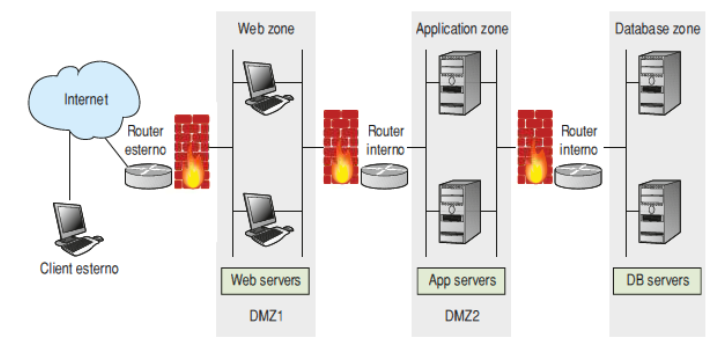
Architettura 3 - TIER
Utilizzando un’architettura dove sono separati Web server, Application Server e il Database, è buona norma mettere il Web server verso l’esterno e collocare nella DMZ l’application server, che di solito ospita la business logic e si collega al DB, il quale è all’interno della LAN.
Nelle ditte in cui la sicurezza dei dati è vitale, è possibile introdurre un sistema di stratificazione della DMZ inserendo anche più di due firewalls e più DMZ.
Reti private virtuali (VPN)
Il termine VPN (Virtual Private Network) nasce alla fine degli anni 90 e si pone come evoluzione delle linee dedicate tra diverse sedi aziendali.
Nel passato infatti i collegamenti tra sedi remote di una stessa società, e quindi tra reti LAN remote, avvenivano solo se era presente una linea di comunicazione fisica dedicata, come per esempio via cavo.
Le reti private dedicate, o reti private “vere e proprie” possiedono alcuni vantaggi:
→ Larghezza di banda sempre disponibile;
→ Nessun problema di accesso;
→ Prestazioni garantite;
→ Sicurezza garantita.
Le reti private dedicate possiedono un rapporto costi/benefici non sempre elevato.
Inoltre queste reti possiedono elevati costi per l’installazione e la manutenzione, oltre a tempi lunghi per la configurazione e riconfigurazione, in quanto non sono scalabili.
Le reti private virtuali (VPN) invece sono configurabili e riconfigurabili facilmente, sono scalabili e offrono un valido rapporto tra costi e funzionalità.
Le VPN possiedono i seguenti vantaggi:
→ Costi ridotti;
→ Multiplexing dei canali logici;
→ Trasparenza, in quanto il gestore della rete pubblica potrebbe anche non essere a conoscenza della VPN;
→ Scalabilità.
Tuttavia le VPN implicano tre problematiche:
→ Velocità di trasmissione non sempre garantita;
→ Autenticazione necessaria;
→ Sicurezza delle trasmissioni con protocolli e tecniche di cifratura e tunneling.
Tunneling
I dati vengono suddivisi in sezioni di dimensioni ridotte, chiamate pacchetti, che vengono trasmessi nel tunnel fino a destinazione.
Durante il tragitto nel tunnel i pacchetti vengono crittati e incapsulati.
Gli strati di tunneling VPN possono essere creati ai seguenti livelli:
→ Livello 2: collegamento dati;
→ Livello 3: livello di rete.
I protocolli coinvolti nel processo di tunneling sono:
- Protocollo PPTP (Point to Point Tunneling Protocol)
In questo protocollo i dati vengono mantenuti al sicuro anche se comuincati su reti pubbliche.
- Protocollo L2TP
Questo protocollo prevede la combinazione dell’utilizzo del PPTP e dell’inoltro a livello 2 ed è usato per supportare le VPN come parte di servizi ISP.
Scenari di applicazione di una VPN
Esistono principalmente tre scenari di applicazione delle VPN:
- Collegamento di due o più sedi aziendali attraverso una rete aperta (site to site);
- Accesso alla rete aziendale da casa o da mobile (End to site);
- Accesso remoto da un computer a un altro (end to end).
VPN site to site
Si applica quando vi è la necessità di collegare più reti locali attraverso un canale di trasmissione pubblico su di una arete di comunicazione virtuale.
Questa situazione potrebbe per esempio verificarsi quando vi è l’esigenza di stabilire un collegamento tra diverse aree aziendali.
Questa struttura richiede la presenza di un router VPN per ciascuna sede, che rappresenta il tunnel VPN tra reti locali.
VPN end to site
Trovano applicazione quando la rete aziendale deve essere accessibile da remoto o da casa.
VPN end to end
Quando l’accesso remoto non avviene su di una rete locale, ma solo da una postazione all’altra.
Una VPN remote desktop viene utilizzanta quando per esempio un impiegato vuole accedere da casa al suo computer direttamente sulla postazione presente sul posto di lavoro.
VPN e sicurezza
Possiamo classificare le reti private in tre categorie, in base al grado di sicurezza offerto:
- Trusted VPN
La sicurezza è affidata al provider (ISP) della rete pubblica.
Le trusted VPN assicurano le proprietà dei percorsi ma non garantiscono un alto livello di sicurezza.
- Secure VPN
I protocolli di cifratura e tunneling sono IPsec e TLS/SSL che assicurano la cifratura dei dati ma non garantiscono le proprietà dei percorsi.
- Hybrid VPN
Si tratta di un tentativo di unire le caratteristiche di entramve le reti VPN.
Categorie d’uso delle VPN
Possiamo suddividere le VPN in tre principali categorie d’uso:
- Remote access
- Intranet
- Extranet
1. Remote access
Permette a un utente di connettersi da una postazione remota alla rete privata.
E’ necessario possedere due componenti:
- NAS (Network Access Server), si tratta di un server di accesso alla rete.
- Software VPN client, consente di connettersi alla VPN usando il proprio computer.
2. 3. Intranet ed Extranet
Abbiamo una VPN di tipo site to site, dove la società consente l’accesso remoto in larga scala
Nella categoria Intranet la comunicazione avviene esclusivamente tra i siti della stessa società, secondo il modello site to site.
Nella categoria Extranet la comunicazione avviene tra società che hanno interessi comuni, sempre secondo il modello site to site.
Wireless e reti mobili
Tra le reti wireless possiamo distinguere due famiglie:
- Reti radiomobili, sono reti wireless dove i terminali possono spostarsi sul territorio senza perdere la connettività con la rete, come la rete cellulare.
- Wireless LAN (WLAN), sono reti wireless che forniscono coperture e servizi tipici di una LAN.
Nelle reti cellulari la connessione deve essere “passata” tra celle adiacenti senza che venga a perdersi il collegamento: questo passaggio prende il nome di handover (o handoff)
Le funzionalità aggiuntive che devono essere svolte in sistemi che presentano utenti in “mobilità” sono:
- Localizzazione
- Registrazione
- Handover
Come per le reti cablate anche per le reti wireless viene fatta una classificazione sulla base della distanza geografica che il segnale trasmesso dai dispositivi che si connettono alla rete può raggiungere.
WLAN (Wireless Local Area Network)
Sono le reti maggiormente diffuse con il oro raggio di copertura che va dai 100 ai 500 metri.
Una rete Wlan è costituita da Station (Sta) e Access Point (AP).
WWAN (Wireless Wide Area Network)
Sono reti wireless di dimensione geografica estesa sino a una decina di kilometri e nascono dall’esigena di raggiungere utenti che difficilmente potrebbero avere connessioni cablate, come paesi di montagna o aree difficilmente raggiungibili o antieconomiche per le normali linee fisse.
Le reti WWAN sono realizzate con diversi standard:
- Prima generazione (1G);
- Seconda generazione (2G);
- Terza generazione (3G);
- Quarta generazione (4G)
- Quinta generazione (5G).
Troviamo anche altre tecnologie wireless, come ad esempio l’irDA, tecnologia di interconnessione dati che utilizza i raggi infrarossi.
Pregi delle WLAN
→ Assenza di cablaggio
→ Facilità di installazione
→ Basso costo
→ Mobilità
Difetti delle WLAN
→ Inaffidabilità del mezzo trasmissivo
→ Sensibilità alle interferenze
→ Privacy
→ Capacità inferiore alle LAN cablate
Tutto il traffico generato/ricevuto dalle stazioni (STA) è trasferito tramite l’Access Point (AP)
Problametiche del Wi-Fi
Capture effect: è un fenome per il quale fra due segnali inviati a una stazione destinatario, il più forte risulta attenuato e rallentato a causa del più debole.
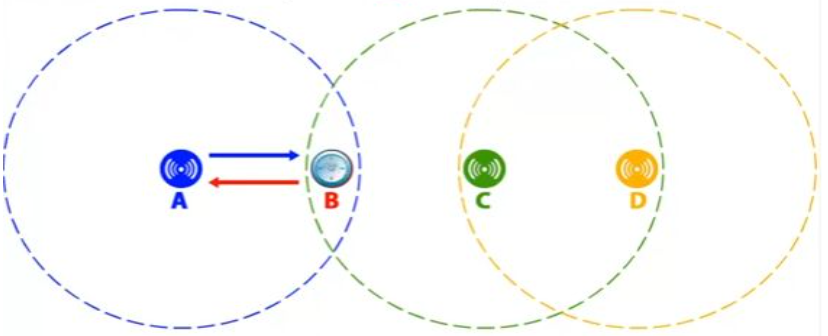
Problema della stazione nascosta (hidden terminal): siano date tre stazioni A, B, C, e A stia trasmettendo a B: se C ascolta il mezzo trasmissivo lo troverà libero e sarà convinta di poter trasmettere a B, ma cominciando a trasmettere disturberà la trasmissione di A.
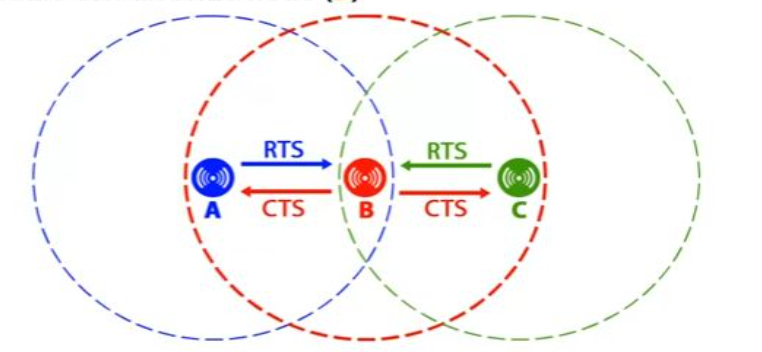
Problema della stazione esposta (exposed terminal): è il problema inverso al precedente, supponiamo che B stia trasmettendo ad A e che C voglia trasmettere a D: ascoltando l’etere, C sentirà la trasmissione di B e concluderà erroneamente di non poter trasmettere, invece essendo D fuori dalla portata di B e A fuori dalla portata di C, le due trasmissioni potrebbero avvenire contemporaneamente.
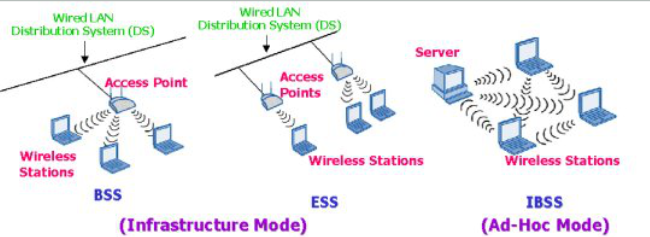
Topologie di rete per IEEE 802.11
Ad hoc Network (Independent Basic Service Set - IBSS)
All’interno del BSS (”independent” BSS) le stazioni possono comunicare direttamente l’una con l’altra senza l’ausilio di un AP.
Basic Service Set (BSS) (Infrastructure mode)
E’ una BSS con un componente chiamato Access Point che fornisce la funzione di relay per la BSS.
La comunicazione tra stazione avviene solo attravero l’AP.
L’AP può fornire la connessione al Distribution System.
Gestione accesso al mezzo 802.3 vs 802.11
In una rete locale Ethernet classica, il metodo di accesso utilizzato per i terminali è il CSMA/CD (Carrier Sense Multiple Access with Collision Detector), per cui ogni terminale è libero di comunicare in qualsiasi momento.
In un ambiente senza fili questa procedura non è possibile dato che le due stazioni comunicanti con un ricettore non si sentono reciprocamente.
Così la norma 802.11 propone il protocollo detto CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance).
Questo protocollo usa un meccanismo per evitare le collisioni basato sul principio di ricevuta di ritorno reciproca tra l’emittente e il ricevente.
La stazione che vuole emettere ascolta la rete. Se la rete è occupata la trasmissione sarà differita.
In caso contrario, se il media è livero per un tempo dato (detto DIFS - Distributed Inter Frame Space), allora la stazione può emettere.
La stazione trasmette un messaggio detto Ready to Send che contiene informazioni sul volume dei dati e sulla velocità di trasmissione.
Il ricevente risponde con Clear To Send se è pronto a ricevere i dati, poi la stazione comincia l’emissione dei dati.
Alla ricezione di tutti i dati emessi dalla stazione, il ricevente invia una ricevuta di ritorno chiamata ACK.
Tutte le stazioni vicine aspettano per un periodo di tempo che considerano necessario alla trasmissione del volume di informazioni da emettere alla velocità annunciata.
Il livello MAC del protocollo 802.11 offre un meccanismo di controllo di errore che permette di verificare l’integrità del frame. Si tratta di una differenza fondamentale con lo standard Ethernet.
In una rete senza fili il tasso di errore è più elevato, ragione per cui un controllo di errore è stato integrato a livello collegamento dati.
D’altra parte il tasso di errore aumenta generalmente con dei pacchetti di dimensione importante, per questo l’802.11 offre un meccanismo di frammentazione, che permette di scomporre un frame in più pezzi.
Il ruolo dell’Access point
Un Access Point è un’entità che permette la distribuzione dei servizi MAC via Wireless Medium (WM) per le stazioni a esso associate.
L’Access Point può essere configurato per funzionare in due modalità:
Root Access Point
Realizza la funzione di DCF e di apparato di associazione per le stazioni presenti nel BSS.
Questa è la configurazione di default che troviamo in ogni AP.
Quando una stazione viene associata all’AP, questo ne scrive l’indirizzo MAC in una tabella che mantiene aggiornata con le nuove connessioni o disconnessioni.
Alla ricezione di un pacchetto dal WM, se l’indirizzo MAC di destinazione è presente nella tabella associata al AP, il pacchetto viene ritrasmesso nel WM, altrimenti se l’indirizzo non è presente nella tabella delle stazioni associate all’AP il pacchetto viene tradotto e trasmesso nella porta wired.
Alla ricezione di un pacchetto dalla porta wired ha un comportamento simile: se l’indirizzo MAC di destinazione è presente nella tabella delle stazioni associate il pacchetto viene tradoto e trasmesso nel WM, mentre se l’indirozzo non è presente nella tabella il pacchetto viene scartato.
Repeater Access Point
L’Access Point funziona come repeater e ha il compito di ritrasmettere i pacchetti che riceve dal WM sul WM.
La sicurezza delle reti wireless
Come ogni comunicazione cablata, la trasmissione senza fili presenta da sempre diverse problematiche relative alla sicurezza.
I problemi principali che riguardano una WLAN sono:
→ Riservatezza: i dati trasmessi attraverso il canale non devono essere intercettati e interpretati;
→ Controllo di accesso: alla rete possono accedere solo gli host autorizzati;
→ Integrità dei dati: i messaggi trasmessi non devono essere manomessi.
Tipologie di attacchi alle reti wireless
- Eavesdropping (intercettazione): possibilità che entità non autorizzate riescano a intercettare i segnali radio scambiati tra una stazione e l’access point.
- Accessi non autorizzati: un intruso si intromette alla rete senza averne l’autorizzazione.
- Interferenze e jamming: tutte le apparecchiature in grado di emettere segnali a radiofrequenza entro la banda di funzionamento della rete rappresentano potenziali sorgenti di interferenza: se esiste la volontà di queste emissioni si parla di jamming.
- Danni materiali: possono essere fatti danni materiali allo scopo di creare malfunzionamenti o interruzioni dei servizi.
La crittografia dei dati
L’operazione di codifica dei dati fornisce riservatezza e integrità.
WEP - Wired Equivalent Privacy
E’ un protocollo di sicurezza a livello data link della pila ISO/OSI.
Venne rilasciato e integrato tra le specifiche di sicurezza delle reti Wi-Fi troppo velocemente. Soltanto dopo l’immissione sul mercato si dimostrò che la sua sicurezzaa non era assolutamente assimilabile a quella delle reti cablate, e che normali utenti informatici avrebbero potuto violare in pochissimo tempo la crittografia utilizzata.
Si basa sul modello a chiave simmetrica mediante un algoritmo che permette di modificare un blocco di testo in chiaro calcolandone lo XOR bit a bit con una chiave di cifratura pseudicasuale.
Codifica
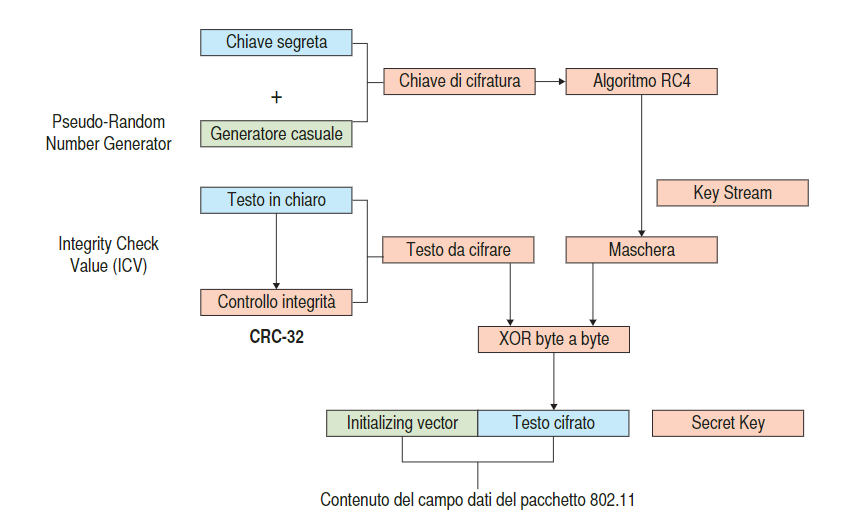
La Chiave di cifratura viene realizzata a partire dalla chiave segreta che viene concatenata con un initialization vector (IV), numero casuale di 24 bit.
Verrà spedito l’initializing vector insieme al testo cifrato e la Secret Key.
Decodifica
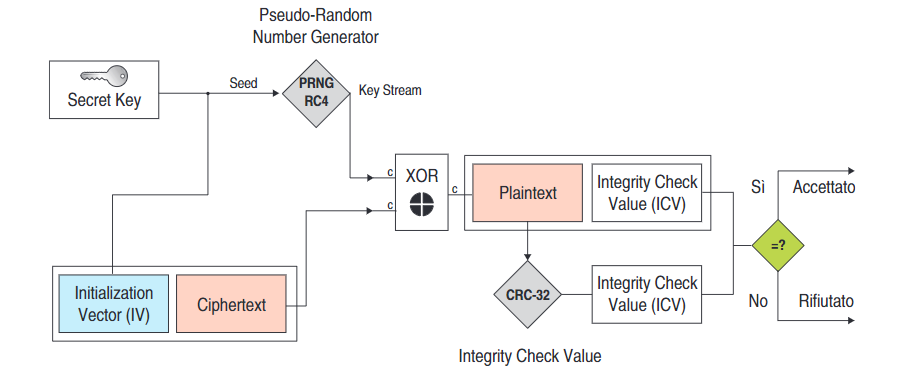
Tramite l’Initialization Vector e la secret key si risale alla key stream la quale, eseguendo lo XOR con il Ciphertext, ci riporta al testo decifrato assieme al suo Integrity Check Value (ICV), che verrà comparato con il nuovo ICV calcolato.
WPA/WPA2
Il Wireless Proteced Access rappresenta una miglioria del WEP, esistono due diverse configurazioni in cui lavora:
- Modalità Personal.
- Modalità Enterprise.
Dove la modalità Personal è consigliata per le applicazioni SOHO - Small Office Home Office.
Le principali migliorie introdotte dal WPA sono nelle dimensioni della chiave, che diventa da 128 bit, e del vettore di inizializzazione, che passa a 48 bit.
WPA utilizza inoltre un nuovo protocollo, il Temporary Key Integrity Protocol (TKIP), che permette di cambiare le chiavi crittografiche utilizzatae dopo un certo numero di dati scambiati.
Inoltre, al posto del CRC - 32 viene utilizzato il Message Integrity Code (MIC) per effettuare il controllo dell’integrità dei dati.
Il MIC è un Message Authentication Codes (MAC), permette di rilevare la presenza di messaggi falsi nella comunicazione.
WPA2
WPA2 è un’aggiornamento del WPA e utilizza l’algoritmo AES al posto dell’RC4 per la cifratura dei dati.
AES può avere diverse modalità di utilizzo, chiamate modalità operative:
- Electronic Codebook (ECB),
- Counter (CTR);
- Cipher-Block Chaining (CBC).
Quella che viene maggiormente utilizzata è la CBC alla quale spesso viene aggiunto un controllo di integrità dei dati MIC, la modalità prende il nome di CBC-MAC.
Autenticazione
E’ il processo tramite il quale un computer, un software o un utente verifica la corretta identità di un altro computer, software o utente che vuole comunicare attraverso una connessione.
Un esempio che tutti noi effettuiamo tutti i giorni è la comune procedura di “login” per accedere a un sistema di elaborazione.
Il sistema di autenticazione 802.1X
La prima forma di autenticazione si basava sulla conoscenza dell’SSID della rete: prende il nome di OSA (Open System Authentication) dove l’Access Point autorizzava chiunque fosse a conoscenza del nome della rete.
Un sistema di autenticazione aggiuntivo è quello che si basa sul filtraggio dei MAC Address dei dispositivi wireless, ma prevede una lunga procedura manuale a opera degli amministratori di rete.
Per garantire un metodo più affiadbile di autenticazione e autorizzazione, l’IEEE 802.11i ha proposto una struttura di protezione WLAN basata sul protocollo 802.1X.
I componenti del sistema di autenticazione sono:
- L’utente di rete (supplicant);
- Un dispositivo di accesso alla rete (Authenticator);
- Un servizio di autenticazione, autorizzazione e accesso (AAA), generalmente un server RADIUS.
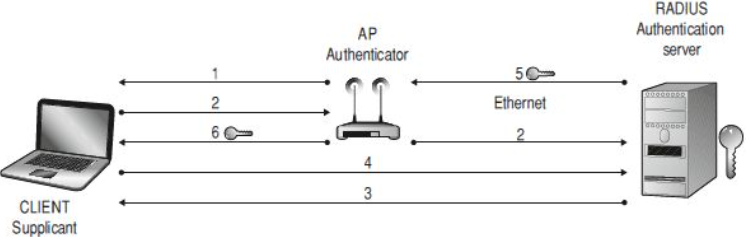
- Un client entra nel raggio d’azione dell’AP, questo richiede le credenziali di accesso al client.
- Il client si identifica all’AP, che inoltra le informazioni ricevute ad un server RADIUS.
- Il server richiede altre credenziali al client per verificarne l’identità, specificando anche il tipo di credenziali richieste.
- Il client invia le proprie credenziali al RADIUS.
- Il server verifica le credenziali: se sono valide invia una chiave di autenticazione crittografa all’AP.
- L’AP utilizza la chiave di autenticazione per trasmettere in modo protetto le chiavi di autenticazione per accedere alla rete.
Modello client/server e distribuito per i servizi di rete
Le applicazioni distribuite possono essere suddivise secondo tre livelli applicativi.
- Il livello presentazione si occupa di gestire la logica di presentazione.
- Il livello della logica applicativa o logica di business si occupa delle funzioni da mettere a disposizione all’utente.
- Il livello di logica di accesso ai dati si occupa della gestione dell’informazione, eventualmente con accesso alle basi di dati.
Questi tre livelli applicativi possono essere installati su vari livelli hardware, detti tier, dove un livello rappresenta una macchina con differente capacità di elaborazione.
Un’applicazione può essere:
- Single tier: i tre livelli sono ospitati su una singola macchina o host.
- Two tier: i tre livelli sono divisi fra una macchina utente, che ospita il livello di presentazione, e la macchina server che ospita il livello di accesso ai dati; il livello di logica applicativa può risiedere sul lato utente o server o essere distribuito fra i due.
- Three tier: i tre livelli risiedono ciascuno su una macchina dedicata.
Le architetture dei sistemi informatici si sono sviluppate ed evolute nel corso degli anni passando da sistemi centralizzati a sistemi distribuiti, maggiormente rispondenti alle necessità di decentralizzazione e di cooperazione delle moderne organizzazioni.
Un sistema distribuito è costituito da un insieme d’applicazinoi logicamente indipendenenti che collaborano per il perseguimento d’obiettivi comuni.
Server farm
I tier fisici possono essere realizzati anche come server farm che viene gestita dagli altri livelli come se fosse un’unica risorsa.
Le server farm possono essere realizzate secondo due principi progettuali:
- Cloning
- Partitioning
Cloning
Su ogni nodo che la compone vengono installate le stesse applicazioni software e gli stessi dati formando in tal modo dei cloni.
Le richieste vengono poi inviate ai vari cloni attraverso un sistema di load - balancing.
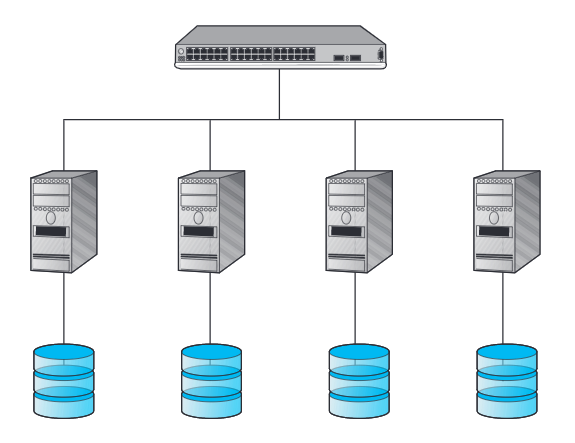
I RACS si possono presentare in due configurazioni:
- Shared nothing;
- Shared disk.
Nella prima configurazione i dati memorizzati sono replicati su ogni clone e risiedono in un disco fisso locale a ogni clone.
Questa configurazione presenta ottime prestazioni per applicazioni di tipo read-only.
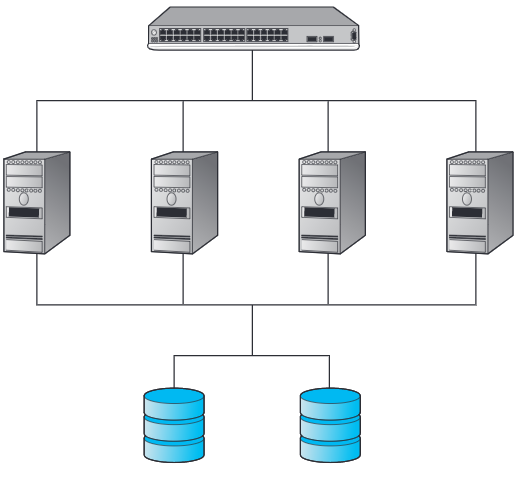
Nella seconda configurazione, detta anche cluster, i cloni condividono un server di memorizzazione che gestisce i dischi fissi.
Partitioning
La tecnica di partizionamento prevede la duplicazione dell’hardware e del software ma non dei dati, che invece vengono ripartiti tra i nodi.
Ogni nodo svolge quindi una funzione specializzata.
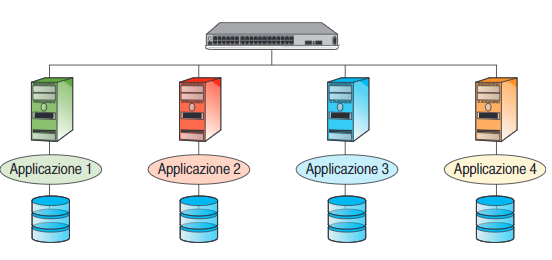
Il partizionamento è trasparente alle applicazioni, le richieste vengono inviate alla partizione che possiede i dati rilevanti.
Tuttavia i dati sono memorizzati su un singolo server, questo significa che in caso di guasto la parte di servizio da esso gestita non risulta più accessibile.
Questa caratteristica è nota come proprietà di graceful degradation.
Per risolvere questo problema si impiega spesso la clonazione dei singoli server, creando in tale modo dei pack.
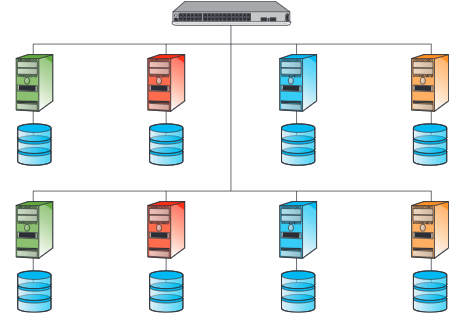
Architetture dei sistemi web
Gli elementi essenziali di un moderno sistema web sono:
- Il web server, che si occupa della gestione delle richieste HTTP;
- Lo script engine, un processo che eseguie script per la generazione di pagine HTML dinamiche;
- L’application server, che assume il ruolo di middle tier e implementa la logica di business.
- Il DBMS server, che si occupa della gestione dei dati.
Configurazione con due tier e unico host
Questa configurazione utilizza una sola macchina fisica che supporta l’esecuzione di web server, script engine e DBMS.
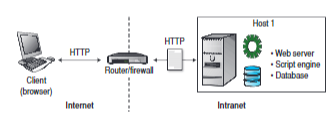
Configurazione con tre tier e dual host
In questa configurazione web server e script engine sono ospitati su una stessa macchina, mentre il DBMS è eseguito su una macchina dedicata.
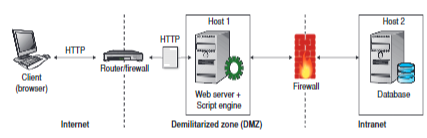
Configurazione con tre tier e server farm
Per ottenere un sistema che migliori le caratteristiche di disponibilità, scalabilità e prestazioni è necessario duplicare i due componenti più critici del sistema: web server e script engine.
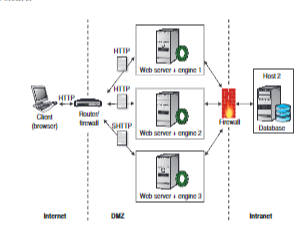
Configurazione con cinque tier e server farm
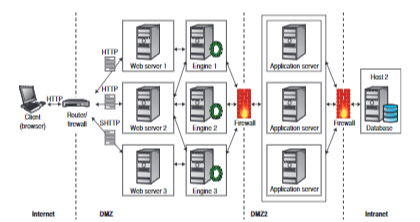
Amministrazione della rete
Attraverso l’amministrazione di rete si implementano le procedure e le politiche necessarie per garantire il corretto funzionamento della rete, a partire dall’autenticazione degli utenti fino al monitoraggio e al mantenimento delle corrette funzionalità degli apparati.
L’autenticazione del client
In un sistema distribuito l’autenticazione riguarda la verifica dell’identità di un utente.
Questa operazione è chiamata autenticazione del client.
Sulla base di questa verifica il sistema permette o nega l’utilizzazione di risorse e l’esecuzione di procedure.
Gli schemi adottati per l’autenticazione sono fondamentalmente tre:
- User to host: è il metodo usato dall’host per autenticare gli utenti.
- Host to host: è il metodo usato dall’host per convalidare l’identità di altri host.
- User to user: è il metodo usato per verificare che i dati elettronici provengano effettivamente dall’utente in questione e non da qualcuno che si spaccia per il mittente.
Amministrazione del sistema operativo
Attualmente i sistemi operativi di rete sono altresì sistemi operativi multiutente. Più utenti possono accedere contemporaneamente al sistema utilizzando le risorse messe a disposizione dal file system.
La sicurezza di questi sistemi è basata sui permessi che vengono associati alle varie risorse, in modo da restringerne l’accesso ai soli utenti abilitati.
L’amminsitrazione centralizzata di un sistema viene garantita nei sistemi windows mediante il servizio Active Directory, che permette la creazione e la modifica di utenti, gruppi, politiche di sicurezza e autorizzazioni relative alle risorse.
Il troubleshooting
Le reti di comunicazione sono oggetti complessi, composti da un insieme interconnesso di apparati hardware e software tramite i quali vengono forniti servizi agli utenti.
La ricerca del problema del sistema e la sua soluzione, unitamente alla produzione della documentazione che ne illustra la soluzione, viene chiamata troubleshooting della rete.
E’ bene generalmente verificare preliminariamente se il problema sussista effettivamente oppure no, in quanto capita che un utente non esperto associ la non fruizione di un servizio di rete come un problema di connettività.
Controllo fisico
Una volta accertato che si tratti di un problema di rete, occorre effettuare alcune verifiche:
- Controllare l’alimentazione
- Controllare la connettività
- Verificare che il LED presente nella scheda di rete sia acceso.
- Riavviare il computer.
Scambio di componenti di rete
Le schede di rete (NIC) possiedono dei particolari LED che indicano lo stato della connessione.
Un LED spento indica chiaramente un problema di connettività tra la scheda e lo switch.
Nel caso di LED spento occorre procedere con le successive operazioni:
- Sostituiamo il cavo che connette la scheda ala presa a muro con un altro;
- Colleghiamo il computer a un’altra presa di rete;
- Verifichiamo la connessione da un altro host della rete.
Se entrambi gli host non accedono ai servizi di rete probabilmente si tratta di un effettivo malfunzionamento della rete.
Verifica della connettività TCP/IP
Analizza la fruibilità dei servizi di rete come per esempio web, mail, FTP, ecc..
Supponiamo di voler effettuare una connnessione a un host mediante TCP/IP, per esempio all’URL di un Web server, si potrebbero verificare tre errori distinti:
- Se otteniamo il tipico errore 404 significa che la rete funziona correttamente, il problema in questo caso risiede sul server;
- Se invece otteniamo un messaggio di errore del tipo “il server non esiste” allora siamo di fronte a un possibile problema di rete;
- Se invece il server risulta raggiungibile mediante l’indicazione del solo indirizzo IP allora siamo di fronte a uno dei seguenti problemi di DNS:
- Potrebbero essere sbagliati i riferimenti ai DNS server nella configurazione di rete dell’host;
- La presenza di un malfunzionamento;
- Potrebbe esserci un problema sui DNS server oppure potrebbero non essere raggiungibili.
Analisi lato client
La verifica che dobbiamo effettuare sul client per prima cosa deve tenere conto della configurazione di rete dell’host, rappresentanta dall’indirizzo IP, subnet mask e default gateway.
Analisi lato server
La prima cosa da fare è escludere che il servizio richiesto sia per qualche motivo attualmente non disponibile. In caso contrario ptremmo provare a eseguire un ping verso l’indirizzo IP dell’host di destinazione.
Se si verifica la connessione tra i due host significa che il problema appartiene a quest’ultimo.
Se le due macchine non si connettono ma l’host riesce a connettersi ad altri indirizzi IP che risiedono sulla stessa LAN della macchina di destinazione significa che il problema consiste in qualche malfunzionamento o non corretta configurazione della macchina destinazione.