SQL
SQL (Structured Query Language) è un linguaggio creato per l’accesso a informazioni memorizzate nei database. Più nel dettaglio, SQL è un linguaggio standardizzato per database basati sul modello relazionale (RDBMS), progettato per le seguenti operazioni:
- DDL → creare e modificare schemi di database (Data Definition Language);
- DML → inserire, modificare e gestire dati memorizzati (Data Manipulation Language);
- DQL → interrogare i dati memorizzati (Data Query Language)
- DCL → creare e gestire strumenti di controllo e accesso ai dati (Data Control Language).
Operatori
Di relazione
In SQL esistono diversi operatori di relazione che risultano utili in molte query nei diversi ambiti del linguaggio (soprattutto DML e DQL):
| = | Uguale |
| > | Maggiore |
| < | Minore |
| >= | Maggiore uguale |
| <= | Minore uguale |
| <> | Diverso. In alcune versioni di SQL è != |
| BETWEEN | In un certo intervallo |
| LIKE | Ricerca un pattern |
| IN | Se è presente in una lista di valori |
Logici
| Operator | Description |
|---|---|
ALL | TRUE if all of the subquery values meet the condition |
AND | TRUE if all the conditions separated by AND is TRUE |
ANY | TRUE if any of the subquery values meet the condition |
BETWEEN | TRUE if the operand is within the range of comparisons |
EXISTS | TRUE if the subquery returns one or more records |
IN | TRUE if the operand is equal to one of a list of expressions |
LIKE | TRUE if the operand matches a pattern |
NOT | Displays a record if the condition(s) is NOT TRUE |
OR | TRUE if any of the conditions separated by OR is TRUE |
SOME | TRUE if any of the subquery values meet the condition |
Di aggregazione
MIN()/MAX()SELECT MAX(stipendio) AS stipendio_massimo FROM dipendenti; SELECT MIN(ore_lavorate) ore_lavorate_minime FROM dipendenti;
COUNT()SELECT COUNT(*) FROM dipendenti;
AVG()SELECT AVG(stipendio) FROM dipendenti;
SUM()SELECT SUM(stipendio) stipendi FROM dipendenti;
DDL → Data Definition Language
Prerequisito: Vincoli di integrità
Un vincolo di integrità è una caratteristica del modello relazionale per le basi di dati ed è necessario che sia soddisfatta tutta l’intera base di dati.
Esistono diversi tipi di vincolo di integrità:
- vincoli intra-relazionali: sono definiti sugli attributi di una sola relazione.
Ritroviamo fra questi vincoli:
NOT NULL
UNIQUE
PRIMARY KEY
- vincoli inter-relazionali: sono definiti su più relazioni contemporaneamente mettendo in corrispondenza informazioni di diverse tabelle correlate attraverso valori comuni di uno o più attributi. Sono chiamati anche vincoli di integrità referenziale (v.i.r.).
Per entrambi i vincoli il sistema blocca i tentativi di violazione segnalandoli.
Per il vincolo di integrità referenziale permette anche di scegliere una reazione da seguire in caso di cancellazione e/o aggiornamento:
CASCADE: la modifica si ripercuote nella tabella interna
SET NULL: mette a null l’attributo di v.i.r. nella tabella interna
SET DEFAULT: inserisce il valore di default nell’attributo di riferimento nella tabella interna
NO ACTION: la tabella interna viene lasciata invariata.
DDL serve a creare e modificare schemi di database. Sono i comandi DDL a definire la struttura del database e quindi dei dati contenuti, ma non fornisce gli strumenti per modificare i dati stessi. I comandi sono: CREATE, ALTER, DROP
Database
# Crea un database
CREATE DATABASE nome;
# Elimina database
DROP DATABASE nome;Table
La tabella SQL è il criterio di organizzazione dei dati in un database relazionale.
La tabella è composta da un insieme di relazioni dette colonne e righe. Nelle righe sono definite le relazioni tra i dati di diverso tipo / proprietà.
Una tabella può essere creata in un database relazionale mediante il comando CREATE del linguaggio SQL:
CREATE# Crea tabella CREATE TABLE nome_tabella( nome_var1 [DOMINIO] (DEFAULT) (VINCOLO), nome_var2 [DOMINIO] (DEFAULT) (VINCOLO), (VINCOLI) );
DROP# Elimina tabella DROP TABLE nome_tabella;
ALTER# Modifica tabella # Aggiungo una colonna ALTER TABLE nome_tabella ADD nome_colonna [DOMINIO]; # Rimuovo colonna ALTER TABLE nome_tabella DROP COLUMN nome_colonna; # Modifico colonna ALTER TABLE nome_tabella ALTER COLUMN nome_colonna [DOMINIO];
Index
Gli indici sono una struttura di dati che contiene puntatori ai contenuti di una tabella disposti in un ordine ascendente, per aiutare il database a ottimizzare le query attraverso una ricerca dicotomica.
Sono simili all’indice di un libro, dove le pagine (righe della tabella) sono indicizzate dal loro numero di pagina. Per creare un indice si utilizza il seguente codice:
CREATE INDEXCREATE INDEX nome_indice ON nome_tabella (lista_colonne);
CREATE UNIQUE INDEXSe viene inserito anche l’attributo
UNIQUErenderà l’attributo della tabella preso in considerazione unico, non consentendo di inserire in input un valore già esistente.CREATE UNIQUE INDEX nome_indice ON nome_tabella (lista_colonne)
DROP INDEXDROP INDEX nome_indice ON nome_tabella;
Vantaggi
- Interrogazioni più veloci.
Svantaggi
- Appesantiscono la memoria (circa 20% in più della dimensione della tabella).
- Rendono più lente le operazioni di modifica.
View
Le viste sono delle query memorizzate con un proprio nome che possono essere considerate simili a tabelle virtuali. Sono una via efficace per mostrare informazioni che arrivano da una o più tabelle.
Le view vengono mantenute per tutta la durata della sessione, poi vengono rimosse. Per creare una vista si utilizza il seguente codice:
CREATE VIEWCREATE VIEW nome_vista AS [SELECT SQL];
DROP VIEWDROP VIEW nome_vista;
Il limite delle view è che non è possibile usare la clausola ORDER BY per specificare un ordinamento. Se proviamo a farlo ci verrà restituito un errore.
DML → Data Manipulation Language
DML fornisce i comandi per inserire, modificare, eliminare o leggere i dati all’interno delle tabelle di un database. La struttura di questi dati deve già essere stata definita tramite il DDL.
Esempi di comando sono: INSERT, UPDATE, DELETE
INSERT INTO
L’istruzione INSERT INTO dell’SQL DML serve ad inserire nuovi record in una tabella
INSERT INTO nome_tabella (lista_colonne) VALUES [lista_valori]
# Oppure senza specificare le colonne
INSERT INTO nome_tabella VALUES [lista_valori]I nomi dei campi si inseriscono tra parentesi rotonde e si utilizza la clausola VALUES per valorizzarli.
UPDATE
UPDATE nome_tabella
SET colonna1 = valore1, colonna2 = valore2, ...
WHERE (condizione);DELETE
DELETE FROM nome_tabella WHERE (condizione);
# Per svuotare una tabella
DELETE FROM nome_tabella;DQL → Data Query Language
Il DQL serve a interrogare i dati memorizzati.
Per farlo si utilizza il comando SELECT.
SELECT
Una select è una query che permette di ottenere un insieme di tuple con i rispettivi attributi
SELECT [lista_attributi | *] FROM lista_tabelle;
# Prendo solo il cognome
SELECT cognome FROM dipendente;
# Prendo tutte le colonne
SELECT * FROM dipendente;
# Con un alias
SELECT cognome AS cognomi_dipendenti FROM dipendente;
# Senza AS funziona comunque
SELECT cognome cognomi_dipendenti FROM dipendente;→ WHERE
# Filtro con delle condizioni
SELECT lista_attributi FROM lista_tabelle WHERE condizione;
# Esempio
SELECT cognome FROM dipartimento WHERE dipartimento = 'marketing' OR dipartimento = 'Produzione';
# Controllo valori nulli
SELECT cognome FROM dipartimento WHERE dipartimento IS NULL;→ DISTINCT
SELECT DISTINCT(attributo) FROM lista_tabelle;
# Prendo tutti i cognomi senza ripetizioni
SELECT DISTINCT(cognome) FROM dipendenti;→ GROUP BY
SELECT *
FROM nome_tabella
WHERE condizione
GROUP BY colonne
ORDER BY colonne;
SELECT COUNT(*) AS numero_dipendenti, età
FROM dipendenti
GROUP BY età;GROUP BY support la clausola HAVING che sostituisce WHERE nelle funzioni di aggregazione.
SELECT COUNT(*) AS numero_dipendenti, età
FROM dipendenti
GROUP BY età
HAVING COUNT(*) > 1;→ ORDER BY
SELECT lista_attributi FROM lista_tabelle ORDER BY ordinamento (ASC|DESC);
# Ordino per cognome (ASC di default)
SELECT cognome FROM dipartimento ORDER BY cognome;
# Ordino per cognome in ordine decrescente
SELECT cognome FROM dipartimento ORDER BY cognome DESC;→ LIKE
SELECT *
FROM Dipendente
WHERE cognome LIKE 'R%i';Prende tutti i dipendenti con cognome che inizia per R e finisce per i (case sensitive).
SELECT *
FROM Dipendente
WHERE cognome LIKE 'R___i';Prende tutti i dipendenti con cognome che inizia per R e finisce per i con 3 caratteri nel mezzo, indicati dal numero di underscore _.
→ Select annidate
SELECT lista_attributi FROM lista_tabelle WHERE condizione [operatore relazione] SELECT SQL- Visualizzare gli impiegati con stipendio superiore allo stipendio medio
SELECT * FROM Impiegato WHERE stipendio > (SELECT AVG(stipendio) FROM Impiegato);
- Visualizzare gli impiegati con stipendio massimo
SELECT nome, cognome FROM Impiegato WHERE stipendio = (SELECT MAX(stipendio) FROM Impiegato);
→ Select insiemistiche
- riprendono i concetti dell’algebra relazionale
- gli operatori utilizzati sono:
UNION
EXCEPT
INTERSECT
{Select SQL} [UNION | EXCEPT | INTERSECT] (ALL) {Select SQL}UNIONSELECT cognome FROM Dipendente UNION SELECT nome FROM Dipendente; /* Rossi Franco Neri Verdi Mario Luigi Anna Anna */
UNION ALLSELECT cognome FROM Dipendente UNION ALL SELECT nome FROM Dipendente; /* Rossi Franco Neri Verdi Mario Luigi Franco */
INTERSECTSELECT cognome FROM Dipendente INTERSECT SELECT nome FROM Dipendente; /* Franco */
EXCEPTSELECT cognome FROM Dipendente EXCEPT SELECT nome FROM Dipendente; /* Rossi Neri Verdi */
Ricapitolando:
UNION: ottengo tutti i cognomi e i nomi
UNION ALL: ottengo tutti i cognomi e i nomi con ripetizioni
INTERSECT: ottengo i cognomi che sono anche nomi
EXCEPT: ottengo tutti i cognomi che non sono anche nomi
Join tra tabelle
SELECT *
FROM Dipendente, Dipartimento
WHERE Dipendente.dipartimento=Dipartimento.nome;→ Per un singolo valore
SELECT Dipartimento.sede
FROM Dipendente, Dipartimento
WHERE Dipendente.dipartimento=Dipartimento.nome;→ Rinominando
SELECT d2.sede
FROM Dipendente d1, Dipartimento d2
WHERE d1.dipartimento=d2.nome;→ Per tutti i valori di una tabella
SELECT d2.*
FROM Dipendente d1, Dipartimento d2
WHERE d1.dipartimento=d2.nome;Il . non è necessario se l’attributo a cui bisogna fare riferimento compare in una sola tabella
Join avanzato
SELECT attributi FROM tabella1 AS alias [tipo-join] join tabella2 AS alias ON [condizioni];Il tipo-join può essere:
- Interno
INNER JOIN(default) → mette insieme le righe che hanno dati comuni tra le due tabelle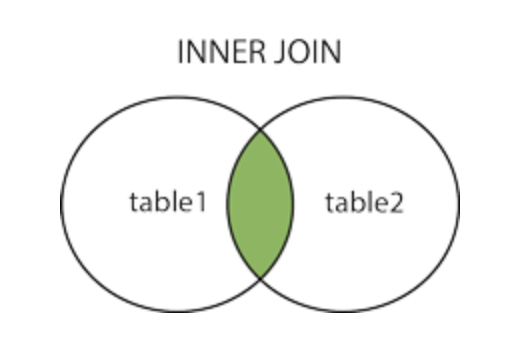
- Esterno
RIGHT OUTER→ outer è opzionale, aggiunge le righe della tabella di destra non coinvolte nell’inner join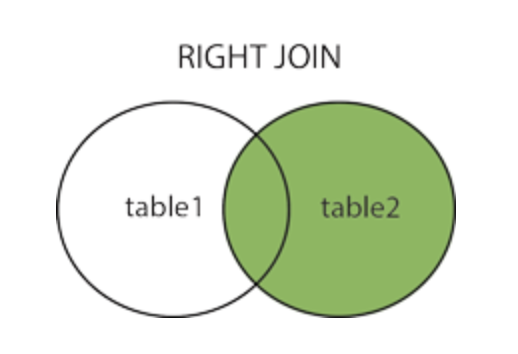
LEFT OUTER→ come right outer ma aggiunge la tabella di sinistra invece che quella di destra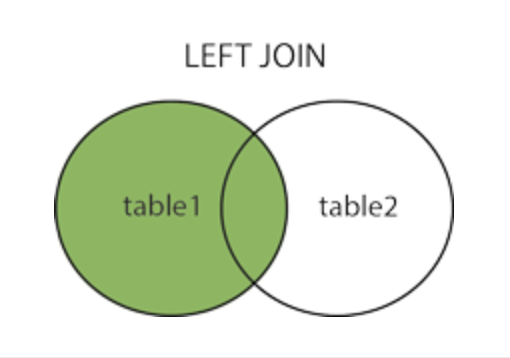
FULL OUTER→ come right outer ma aggiunge sia le righe della tabella di sinistra che quelle della tabella di destra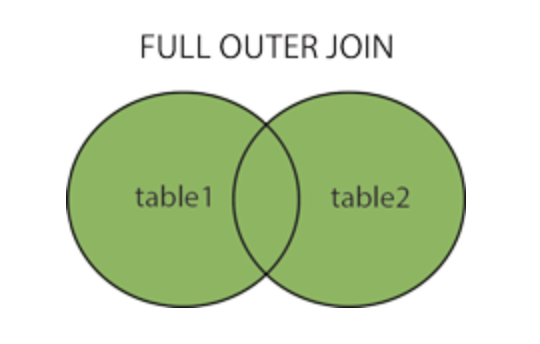
SELECT *
FROM Dipartimento d INNER JOIN Dipendente di ON d.nome=d.dipartimentoDCL → Data Control Language
Privilegi
Ogni componente dello schema può essere protetto.
Il possessore della risorsa assegna dei privilegi agli altri utenti.
Tipi di privilegi:
INSERT
UPDATE
DELETE
SELECT
USAGE
- …
→ Per concedere un privilegio:
GRANT privilegio ON risorse TO utenti (WITH GRANT OPTION)
# WITH GRANT OPTION permette agli utenti di concedere a loro volta privilegi su quella risorsa→ Per revocare un privilegio:
REVOKE privilegio ON risorse TO utenti
# per revocare la possibilità di assegnare privilegi
REVOKE GRANT OPTION ON risorse to utenti